

Over 90% of data jobs still list SQL as a must-have skill—even in machine learning roles.
At the same time, Pandas is downloaded over 60 million times a month, powering everything from Kaggle notebooks to billion-dollar ML pipelines.
So… which one should you use?
Or better—when should you use SQL over Pandas, and vice versa?
I faced the same question while working on a client project last semester.
We had terabytes of raw logs in PostgreSQL and a tight deadline.
At first, I pulled everything into Pandas.
Big mistake. It choked.
Switched to SQL for the heavy lifting, then refined results in Pandas.
That combo? Magic.
This post breaks down exactly when to use SQL, when Pandas makes more sense, and why you probably need both.
Let’s dive in.
What’s the Core Difference Between SQL and Pandas?
SQL is for talking to databases. Pandas is for playing with data in Python. Simple.
SQL is a domain-specific language built to query and manage structured data inside relational databases like PostgreSQL, MySQL, or BigQuery.
Pandas is a Python library that works in-memory and is designed for quick, flexible data manipulation—ideal for small to medium datasets.
SQL works best when your data lives in a production-grade, persistent system. It’s great for large-scale queries, joins, filtering, and ensuring data integrity.
Pandas, on the other hand, is your go-to for quick experiments, data cleaning, or prepping a dataset for a machine learning model.
The biggest difference? SQL is built for scale. Pandas is built for speed.
SQL queries get optimized by the database engine—indexes, cache, and query planners make large data processing fast and reliable.
Pandas loads everything into your RAM. That’s powerful but limited. A 2GB CSV might be fine—10GB? You’re crashing your machine.
I once tried loading a 50M row CSV into Pandas on my 16GB laptop. It worked—for 2 minutes. Then everything froze.
SQL is strict. Pandas is loose.
If you try to insert a string into an integer column in SQL, it throws an error. That’s annoying—but helpful.
In Pandas, it might just let it slip through. You don’t even realize until your model breaks.
Wes McKinney, the creator of Pandas, once said: “I wanted a powerful tool for Python that made working with data as easy as R but with more flexibility.”
That’s what Pandas is—a Swiss army knife for Python data work.
SQL, on the other hand, is a specialized power tool. Less flexible, but incredibly effective for heavy lifting.
A 2024 Stack Overflow survey showed that over 57% of data professionals use both SQL and Pandas regularly.
That’s because they’re not rivals—they’re teammates.
So when people ask, “Which one should I learn or use?”—my answer is always: Depends on the job.
If your work involves large shared datasets, reports, or real-time dashboards—go SQL.
If you’re exploring data, building models, or running quick experiments—go Pandas.
And when you’re working on real-world projects, you’ll almost always use both. I’ve seen SQL pipelines feeding directly into Pandas scripts that power business decisions. It’s not either-or.
It’s knowing when to use what—and how to make them work together.
Pandas vs SQL Syntax Comparison
| Operation | Pandas Syntax | SQL Query Syntax |
|---|---|---|
| Filtering Data | df[df['column'] > value] | SELECT * FROM table WHERE column > value; |
| Multiple Conditions | df[(df['a'] > 10) & (df['b'] < 20)] | SELECT * FROM table WHERE a > 10 AND b < 20; |
| Grouping Data | df.groupby('column') | SELECT column, COUNT(*) FROM table GROUP BY column; |
| Aggregation (Mean) | df.groupby('col')['val'].mean() | SELECT col, AVG(val) FROM table GROUP BY col; |
| Aggregation (Multiple) | df.groupby('col').agg({'a': 'mean', 'b': 'sum'}) | SELECT col, AVG(a), SUM(b) FROM table GROUP BY col; |
| Joining Tables (Inner) | df1.merge(df2, on='key') | SELECT * FROM t1 JOIN t2 ON t1.key = t2.key; |
| Joining (Left) | df1.merge(df2, on='key', how='left') | SELECT * FROM t1 LEFT JOIN t2 ON t1.key = t2.key; |
| Joining (Outer) | df1.merge(df2, on='key', how='outer') | SELECT * FROM t1 FULL OUTER JOIN t2 ON t1.key = t2.key; |
| Sorting Data | df.sort_values('column', ascending=False) | SELECT * FROM table ORDER BY column DESC; |
| Renaming Columns | df.rename(columns={'old': 'new'}) | SELECT old AS new FROM table; |
| Dropping Columns | df.drop('column', axis=1) | SELECT col1, col2 FROM table; (exclude the column you don’t want) |
| Selecting Specific Columns | df[['col1', 'col2']] | SELECT col1, col2 FROM table; |
| Adding New Column | df['new'] = df['a'] + df['b'] | SELECT a + b AS new FROM table; |
| Changing Data Type | df['col'] = df['col'].astype(float) | CAST(column AS FLOAT) |
| Null Handling (isnull) | df[df['col'].isnull()] | SELECT * FROM table WHERE col IS NULL; |
| Null Handling (fillna) | df['col'].fillna(0) | SELECT COALESCE(col, 0) FROM table; |
| Dropping NA Rows | df.dropna() | SELECT * FROM table WHERE col IS NOT NULL; |
| Distinct Values | df['col'].unique() | SELECT DISTINCT col FROM table; |
| Value Counts | df['col'].value_counts() | SELECT col, COUNT(*) FROM table GROUP BY col; |
| Reset Index | df.reset_index() | (SQL doesn’t need this – tables are already index-free) |
| Apply Function (lambda) | df['col'].apply(lambda x: x + 1) | SELECT col + 1 FROM table; |
| Pivot Table | df.pivot_table(index='A', columns='B', values='C', aggfunc='sum') | SELECT A, B, SUM(C) FROM table GROUP BY A, B; |
| Cumulative Sum | df['cumsum'] = df['col'].cumsum() | SELECT col, SUM(col) OVER (ORDER BY id) AS cumsum FROM table; |
| Row Number | df['row_num'] = np.arange(1, len(df)+1) | SELECT ROW_NUMBER() OVER (ORDER BY col) AS row_num FROM table; |
| Window Function (Rolling) | df['rolling'] = df['col'].rolling(3).mean() | SELECT AVG(col) OVER (ORDER BY id ROWS 2 PRECEDING) FROM table; |
📌 Notes:
- SQL is for querying databases, while Pandas is for in-memory dataframes.
- Some advanced Pandas operations (like rolling windows) require more complex SQL window functions.
- Not all SQL systems support advanced features like
ROW_NUMBER()orWINDOW FUNCTIONS(older MySQL versions may not).
When Does SQL Make More Sense?
Use SQL when you’re dealing with large, structured datasets that live in a proper database. It’s built for that. Simple as that.
Querying millions—even billions—of rows? SQL handles it without breaking a sweat. Pandas? Not really.
I once tried loading 4GB of production data into a Pandas DataFrame on my 8GB RAM machine… yeah, never doing that again 😵💫.
Large, production-scale databases
SQL scales. It’s optimized to work on disk-based data with indexes, partitions, and joins that actually perform well.
According to Stack Overflow’s 2023 Developer Survey, over 50% of developers use SQL regularly.
Not because it’s fancy—but because it works.
That’s why every serious backend system (PostgreSQL, MySQL, Snowflake, etc.) still uses it at the core.
Pandas doesn’t even try to replace that—it runs in-memory, so you’re limited by RAM.
Built-in security and access control
Databases running SQL come with user roles, authentication, and permissions baked in.
That means if you’re working in a company and handling sensitive financial or user data, SQL keeps things secure and trackable.
Pandas? It’s just a Python object.
You can copy it, share it, delete it—and no one would know. 😬
Real-time data integrity
SQL supports ACID compliance—that’s Atomicity, Consistency, Isolation, Durability.
These boring-sounding words are the reason your online banking app works without losing your money when the internet drops.
Pandas isn’t even playing in that league.
It doesn’t manage concurrent access or transactions.
If two people edit the same DataFrame in parallel, good luck 😅.
Better for Data Warehousing and ETL
If you’re building automated pipelines, SQL tools like dbt, Airflow, or BigQuery let you schedule, transform, and monitor jobs.
With Pandas, you’re mostly scripting things manually.
I had a project with time-triggered daily transformations—it was a nightmare to manage in Pandas until I moved logic into SQL views and scheduled it with dbt.
Huge productivity boost.
As Emily Hawkins, a senior data engineer at Spotify, said: “When data size and reliability matter, SQL is home base. Pandas is for play.”
Bottom line? SQL is better for serious, scalable, secure data work.
Use it when you’re not just analyzing data—but running a business on it.
When Should You Prefer Pandas?
If you’re working with data locally, prefer fast experiments, or just want to play with CSVs quickly, Pandas wins—every single time.
It’s built for in-memory processing, and that makes it lightning-fast for small to medium-sized datasets.
I remember during a sentiment analysis project, I loaded a dataset of 200K tweets and finished cleaning, filtering, and vectorizing everything in Pandas—under 10 minutes, no DB needed.
Unlike SQL, which expects data to sit in a structured database, Pandas doesn’t care about schemas.
You can mix strings with floats, reshape tables, fill missing values, apply any custom logic—no complaints.
This is why most data scientists, ML engineers, and Python devs stick to it.
It’s part of the PyData stack, so it plays well with NumPy, Matplotlib, scikit-learn, and Jupyter.
The moment you try to do one-hot encoding or feature scaling inside SQL, you’ll see how limited it is.
Pandas, on the other hand, has built-in methods for all of that.
And flexibility aside, Pandas is also way easier to debug.
If something breaks, it throws a clean Python error.
With SQL, especially across tools like BigQuery or Redshift, debugging can be a slow and frustrating process.
And don’t even get me started on SQL dialect issues—PostgreSQL and MySQL handle the same queries differently, which can ruin your cross-platform workflows.
Also, you’re not alone in loving Pandas.
According to Stack Overflow’s 2023 Developer Survey (source), Pandas is the 6th most loved library among all developers—and #1 in the data science space.
And that’s despite being slower than SQL for large-scale joins or aggregations.
Why? Because you’re not building production pipelines in Pandas.
You’re experimenting, exploring, learning, and cleaning data for the next model.
For that, nothing beats the freedom and speed of Pandas.
Still, it’s not perfect.
Once your data crosses a few million rows, Pandas can get slow or crash due to memory limits.
Yes, there are libraries like Dask, Modin, or Vaex, which claim to scale Pandas, but they’re not always stable or beginner-friendly.
I tried Dask once for a customer churn model, and while it technically scaled to 10M rows, the setup overhead wasn’t worth the marginal speed gains.
Also, Pandas lacks concurrent access, row-level security, and transaction support, so forget about using it in multi-user, production scenarios.
In short, use Pandas when you’re building locally, exploring data, doing ML, or when speed of development > speed of query.
It’s flexible, beginner-friendly, and insanely powerful—but don’t expect it to scale like SQL or handle enterprise-level access control.
SQL vs Pandas: Performance Comparison
If you’re wondering which is faster—SQL or Pandas, here’s the short answer: SQL wins on scale, but Pandas wins on speed for small tasks. Now let’s break it down.

Small datasets
When you’re working with a few thousand rows, Pandas is lightning-fast. It loads everything into memory and runs like butter.
I once parsed a messy Excel export with Pandas in under 2 seconds—try doing that in raw SQL and you’ll go nuts tweaking syntax for nulls and weird types. But this speed comes with a price: RAM.
Even a 300MB CSV can balloon in memory to several GBs depending on the operations. I’ve had my Jupyter crash more times than I can count because I forgot to del a DataFrame 🧠💥.
Medium to large datasets
This is where SQL crushes it. It’s built for handling millions to billions of rows using optimized indexes, caching, and execution plans.
A benchmark by Mode Analytics (https://mode.com/blog/pandas-vs-sql/) showed SQL querying a 10-million-row dataset in seconds, while Pandas struggled unless heavily optimized.
Pandas wasn’t made for this scale—and although tools like Dask or Vaex try to fill that gap, they’re not production-standard yet.
I tried using Dask on a 5GB CSV and got faster results, but setting it up took longer than writing the actual SQL query 🤦♂️.
Does Pandas scale?
Not really—not without help.
The native Pandas engine is single-threaded, memory-bound, and not lazy.
Sure, you can “scale” it with modin, dask, or polars, but let’s be honest—real-world teams rarely deploy those in business pipelines.
Most companies rely on PostgreSQL, BigQuery, Snowflake, or similar SQL engines because they’re battle-tested, secure, and maintainable.
As Max Kuhn, the creator of the ‘caret’ package in R, once said: “Reproducibility at scale isn’t about speed. It’s about stability.” That’s what SQL gives.
So if your data is small, temporary, and in-memory—Pandas is great for exploration.
But if you’re building something serious, reliable, and used by others—SQL is the better long-term bet.
👉 Bottom line: Pandas feels faster, but SQL actually scales.
Use Pandas for speed, SQL for stability.
Which One Should You Learn First?
It depends on your goals.
If you’re heading into data analysis, BI, or backend-heavy roles, start with SQL.
It’s the industry’s bread and butter.
Over 82% of job listings in data roles require SQL, according to Dataquest.
Even most machine learning roles casually drop “SQL preferred” in the fine print.
It’s not optional—it’s expected.
But if you’re leaning into data science, automation, or ML, start with Pandas.
It flows naturally with Python, making data wrangling feel like writing scripts, not queries.
I still remember struggling with deeply nested JSON fields in SQL—total nightmare.
With Pandas? Just json_normalize() and done.
It feels right if you’re a Python person.
Business roles vs Technical roles
Business analysts, product managers, or marketers? Stick with SQL.
It’s structured, simple, and gets you to the answer fast.
Most companies already have clean data sitting in relational databases.
I once helped a startup CMO make sense of churn rates using just 4 lines of SQL.
No Pandas, no imports, no Jupyter Notebook needed.
Engineers, ML devs, or automation guys? You’ll want Pandas.
It’s way more flexible when you’re dealing with real-world messy datasets.
Plus, Pandas is deeply tied to the Python ML ecosystem—it’s how you prep data for scikit-learn, XGBoost, or TensorFlow.
As Jake VanderPlas (author of Python Data Science Handbook) said: “You can’t do real data science in Python without Pandas.”
But here’s the twist: Pandas doesn’t scale well alone.
It loads everything in RAM.
Try joining two 5GB CSVs and your laptop might start melting ☠️.
SQL, on the other hand, handles huge data like a pro.
That’s why most professionals end up using both—query with SQL, refine with Pandas.
That’s been my workflow for over a year now, and honestly, nothing beats that combo.
TL;DR?
➡️ Want a job fast? Learn SQL.
➡️ Want to build smart things? Learn Pandas.
➡️ Want to stand out? Learn both.
SQL + Pandas: Why Not Both?
You don’t need to choose between SQL and Pandas. Most real-world workflows actually use both, and that’s not just a convenience—it’s a best practice.
For example, in one of my past university projects, we were analyzing customer behavior from a PostgreSQL database. Writing heavy joins in Pandas was a nightmare.
So I pushed all the aggregation logic to SQL, then used pandas.read_sql() to pull the cleaned data straight into Python for visualization and modeling. It saved hours, and the whole pipeline was smoother than trying to brute-force it all in one tool.
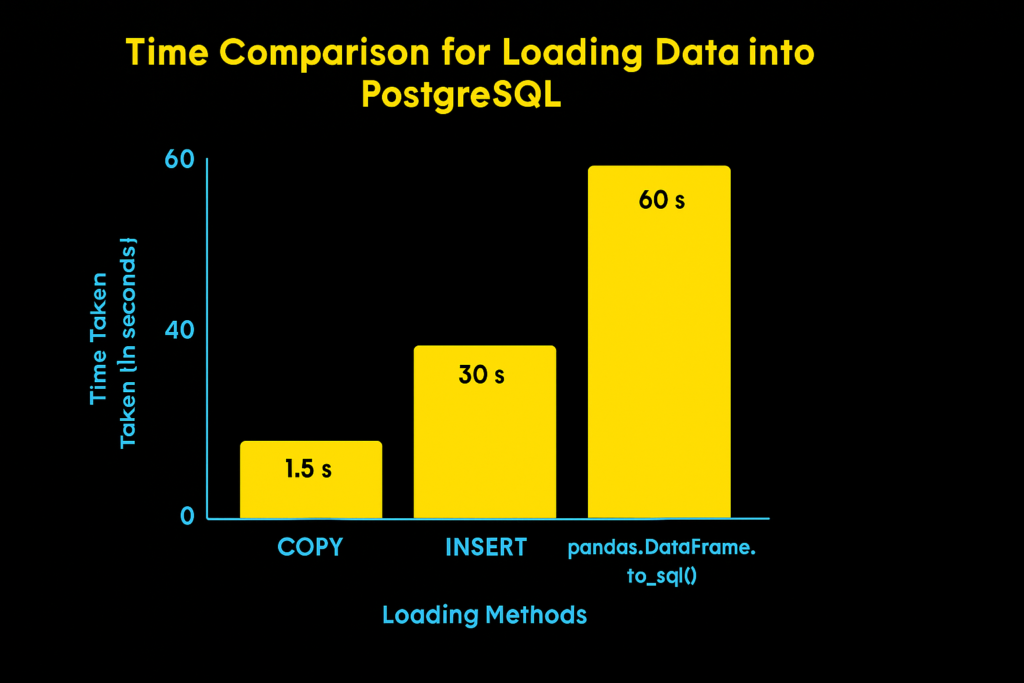
COPY (native PostgreSQL method), INSERT (individual row insertion), and pandas.DataFrame.to_sql() (Pandas method).Here’s the truth: SQL is amazing at filtering, aggregating, and joining structured data efficiently, especially when you’re dealing with millions of rows. But Pandas gives you flexibility, expressiveness, and full integration with Python’s data ecosystem, which SQL simply can’t match.
It’s like using SQL to clean the room and Pandas to decorate it.
Even Wes McKinney, the creator of Pandas, said in an interview with Real Python: “Pandas wasn’t built to replace SQL. It was built to complement it.” And that’s exactly how top data teams operate.
According to Stack Overflow’s 2024 Developer Survey, over 67% of data professionals report using both SQL and Pandas in the same workflow. Not because they have to—because it works better.
Still, there’s a gotcha. If you’re constantly switching between both tools without clear boundaries, your codebase can get messy.
I’ve seen startups where 5 different scripts were pulling similar queries in Pandas and SQL, but none were optimized or version-controlled. Data inconsistency crept in silently.
So here’s a practical tip I follow: Use SQL for extraction, Pandas for transformation. This approach avoids redundancy, keeps your logic clean, and lets you version and reuse code more easily.
Plus, tools like SQLAlchemy, DuckDB, or even Polars now blur the line between SQL and Pandas even further—so you get best of both worlds in a single script.
And if you’re working on ML pipelines, this combo becomes critical. SQL gives you production-level data stability, while Pandas keeps your experimentation agile.
Bottom line: Don’t frame it as SQL vs Pandas. Instead, ask: Where should SQL stop and where should Pandas begin? That’s how professionals think.
Final Thoughts: Think in Terms of Use Case, Not Tools
Don’t treat SQL and Pandas like rivals. They’re tools, not teams.
Each one shines in different stages of the data workflow.
SQL is built for querying massive structured data, ensuring speed, consistency, and scalability.
Pandas thrives in flexible, Python-driven environments, perfect for data cleaning, transformation, and modeling.
Most real-world projects use both—I’ve personally never worked on a serious ML pipeline that didn’t start with a SQL query and end with a Pandas DataFrame.
If you’re still stuck choosing, don’t overthink.
Start with what your data demands.
Huge production tables? Go with SQL.
CSVs on your local machine? Use Pandas.
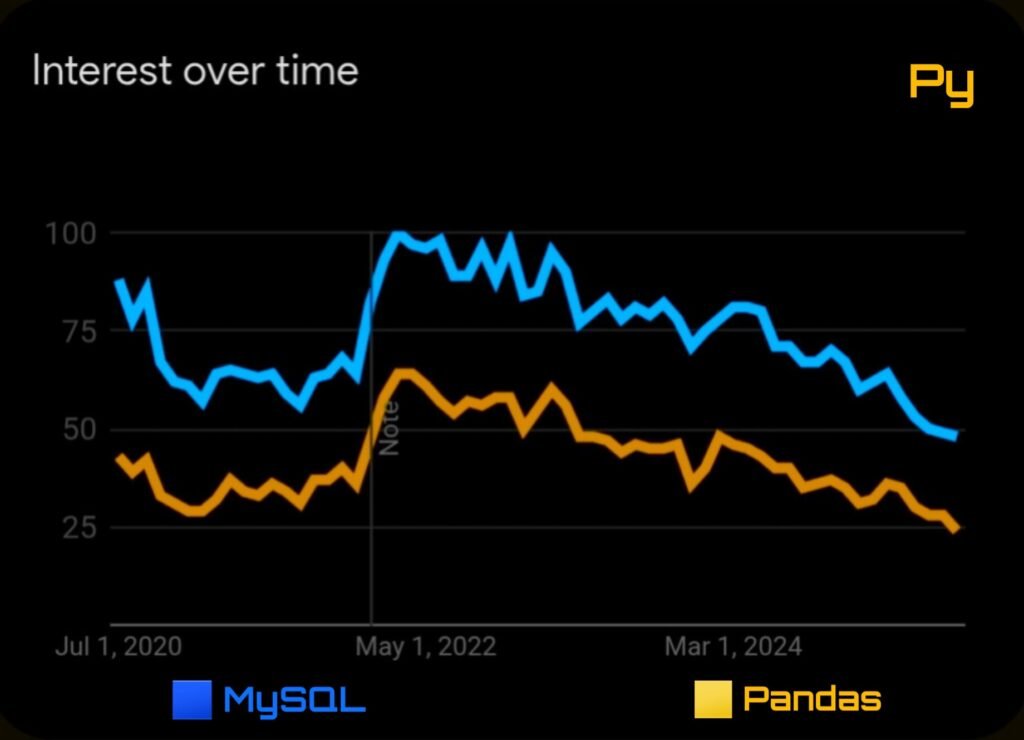
In fact, Google Trends shows that interest in Pandas is growing faster in data science circles, while SQL remains dominant in business analytics roles.
Neither is “better”—but ignoring one will limit your effectiveness.
Sure, Pandas is friendlier and more “code-like” for Python users, but it breaks easily on large datasets.
SQL might feel rigid, but that rigidity is what makes it reliable at scale.
One quote I loved from Max Humber (author of Pandas Cookbook): “Pandas is like Excel with superpowers—but Excel won’t run your backend.” ⚡
Bottom line: Know both. Use each when it makes sense.
That’s the difference between a tool user and a problem solver.
And in a world where data engineers are expected to wear many hats, being fluent in both SQL and Pandas is not just smart—it’s career armor.
Written by Pythonorp, a backend-heavy ML enthusiast who once tried to run a 10GB join in Pandas and nearly cried 😅