

Most teams pick an ML framework too early.
And they regret it too late.
I have seen this happen again and again.
A team ships fast.
Costs explode.
Or control disappears.
That is why people keep asking one question.
Open-source vs proprietary machine learning frameworks. Which one should I choose?
Here is the straight promise.
By the end of this post, you will know which option fits your team, budget, risk level, and long-term plan.
No theory.
No fluff.
Only decisions you can actually defend.
Let me hit you with a fact first.
According to Stack Overflow surveys and cloud provider disclosures, most production ML systems run on open-source frameworks, yet most ML spending flows to proprietary platforms.
That gap tells a story.
People build with open-source.
People pay for convenience.
- Why are people even comparing open-source vs proprietary machine learning frameworks?
- What do we really mean by “open-source” and “proprietary” in ML today?
- Is open-source really free in production environments?
- Are proprietary ML frameworks really black boxes?
- Which option gives you more long-term leverage?
- Let’s talk about hidden costs vs visible convenience
- Short verdict based on real evidence
- What happens when your ML system actually succeeds and scales?
- Who controls your data, models, and decisions?
- How does this choice affect hiring, teams, and future talent?
- Which option is safer for non ML first businesses?
- Can you mix open-source and proprietary ML frameworks safely?
- What do most comparison articles get completely wrong?
- How should founders, CTOs, and product leaders decide step by step?
- Open-source vs proprietary ML frameworks final verdict
- FAQs
- Is open-source ML always better than proprietary frameworks?
- Do proprietary ML frameworks lock you in permanently?
- Can startups start proprietary and switch later?
- Which option fits regulated industries best?
- What is the biggest hidden cost in open-source ML?
- What is the biggest risk of proprietary ML platforms?
Why are people even comparing open-source vs proprietary machine learning frameworks?
People compare these because they want to decide what gives better outcomes for their ML projects.
Some folks think open-source is cheap and flexible.
Others think proprietary tools are easier and safer.
Both sides have stories, costs, and risks 😅 Ready? Let’s dig into what matters most.
Here’s the truth most blogs ignore:
This comparison isn’t just about cost.
It’s about control, risk, talent, long-term ownership, and team speed.
Developers argue open-source gives freedom.
Managers care about support and predictability.
Enterprises care about compliance and deployment safety.
So the real question is:
Which choice matches your team and goals?
There isn’t one answer that fits everyone.
What do we really mean by “open-source” and “proprietary” in ML today?
What exactly is “open-source”?
Open-source means you can see, modify, and extend the code.
Examples include well-known frameworks like TensorFlow, PyTorch, CatBoost, MXNet, etc. These let you build, customize, and host your own tools. They’re developed in the open and have huge communities.
Open-source gives you full control and transparency.
You own the code, the models, the data configurations, and the deployment details.
What do we mean by “proprietary”?
Proprietary means the code and tools are owned by a company.
You get them as a product or service.
Examples here (ML platforms like AWS SageMaker, Google Vertex AI, Azure ML Workspaces, etc.) provide managed environments, scaling, and support.
You pay for convenience, reliability, and pre-built automation.
That’s the big difference in simple terms.
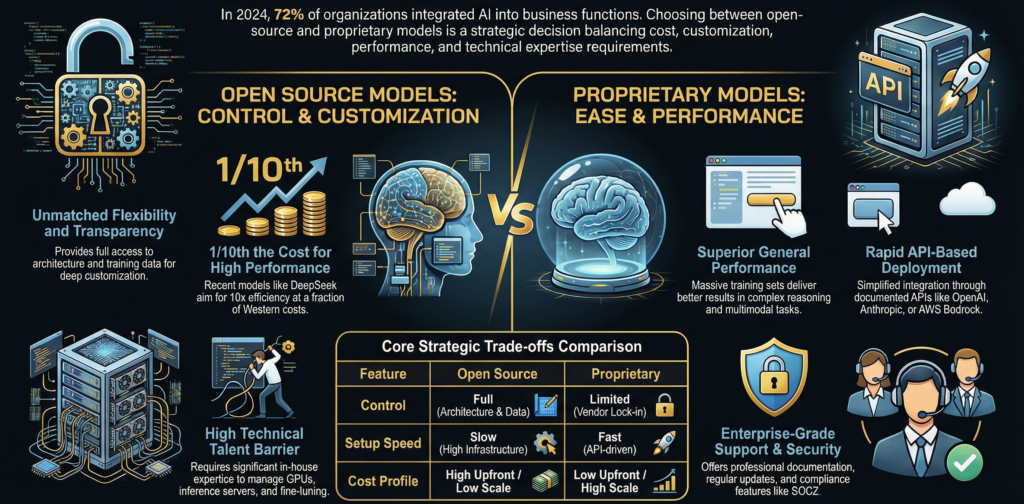
| Aspect | Open-source ML frameworks | Proprietary ML frameworks |
|---|---|---|
| License cost | No license fee | Paid subscription or usage based |
| Code access | Full access to source code | No access to internal code |
| Customization | Fully customizable | Limited to vendor options |
| Transparency | High transparency | Limited visibility |
| Support | Community driven support | Vendor provided support |
| Vendor lock-in | Low risk | High risk |
| Compliance control | Full control over audits | Depends on vendor tools |
| Innovation speed | Community driven | Vendor roadmap driven |

Is open-source really free in production environments?
Short answer: No. 🧠
Open-source tools themselves often cost zero license fees.
But they are not free to operate.
You still need:
- Engineers to configure them
- Infrastructure (servers, GPUs)
- DevOps and CI pipelines
- Monitoring and model maintenance
These costs can add up fast, especially in production environments.
I’ve seen startups excited about “free ML” only to realize they must invest in 2–3 additional engineers and heavy cloud costs for reliable production use.
So the real cost is engineering time and infrastructure.
Sometimes it exceeds what you might pay a vendor over 3 years.
Open-source is free to acquire.
It is not free to run reliably.
That’s an important nuance most articles skip.
Are proprietary ML frameworks really black boxes?
Not always.
“Black box” means you cannot see or modify the internals.
With many proprietary platforms you cannot inspect the training pipeline, weights, or optimization logic.
This matters when you:
- Need compliance
- Must explain predictions
- Want reproducibility
Auditors and regulators hate black boxes because they cannot verify what’s inside.
At the same time, many proprietary vendors add explainability tools, dashboards, and integrated logs.
You get visibility to outcomes, not internals.
That’s a real trade-off.
So yes, many proprietary systems act like black boxes.
But that’s sometimes intentional design for simplicity and trust in enterprise settings.
Which option gives you more long-term leverage?
This is where the conversation gets real.
People chase short-term wins like licensing cost and deployment speed.
But real leverage comes from:
Ability to change tools without starting over
Ability to own your entire stack
Ability to integrate future innovations
Why open-source often wins the long-game
Open-source means you control the code and the stack.
If a library gets discontinued, you can fork it.
If you need new algorithms, you add them.
You aren’t stuck waiting for a vendor roadmap.
Communities constantly improve tools.
That means you benefit from global contributions.
My own experience echoes this:
I once switched a team from a proprietary workflow to open-source libraries.
We gave up some built-in support.
But we gained full visibility, no surprise upgrades, and no vendor pricing changes.
This gave us confidence to innovate long-term.
Why proprietary tools sometimes make sense
Proprietary ML platforms solve a real problem:
They remove operational complexity.
They deal with:
- Infrastructure
- Scaling
- Security updates
- Load balancing
- Patching
That matters when the team is small or the deadline is tight.
You pay money for simplicity.
Some companies want to channel engineering time into product features instead of ML infrastructure.
That is a legitimate choice.
So the real decision is not free vs paid.
It is:
Engineering freedom vs operational simplicity.
Let’s talk about hidden costs vs visible convenience
Open-source tools are often admired for being free.
But let’s be honest.
They have “hidden cost vectors”:
- Documentation inconsistencies (not all libraries are well documented)
- Community support (helpful but not guaranteed)
- Integration challenges across pipelines and tools
- Security patching and governance 🔐
Proprietary systems do the opposite:
They show you:
- What you pay
- What support you get
- SLAs and uptime guarantees
But you trade:
- Customization
- Code ownership
- Deep transparency
And that trade matters for product teams that care about controlling risk.
| Scaling factor | Open-source frameworks | Proprietary platforms |
|---|---|---|
| Auto scaling | Custom built | Built-in |
| Failure recovery | Engineer managed | Vendor managed |
| Monitoring | Custom tools | Integrated dashboards |
| Model retraining | Manual pipelines | Automated workflows |
| Operational stress | High without MLOps | Lower |
| Control at scale | Very high | Medium |
My real-world experience with both
I once worked on an ML feature using a proprietary platform.
We launched fast.
We felt safe with SLAs and managed infra.
But six months later we hit a pricing spike that doubled our monthly bill.
There was no negotiation, because that was tied to usage scaling.
That sucked 🤦♂️
When we moved to open-source workflows later, we gained:
- Predictable engineering costs
- Control over scaling choices
- No surprise bills
But we also learned the hard way we needed good DevOps engineers.
There was no magical free lunch.
That’s the honest truth teams need before choosing.
Short verdict based on real evidence
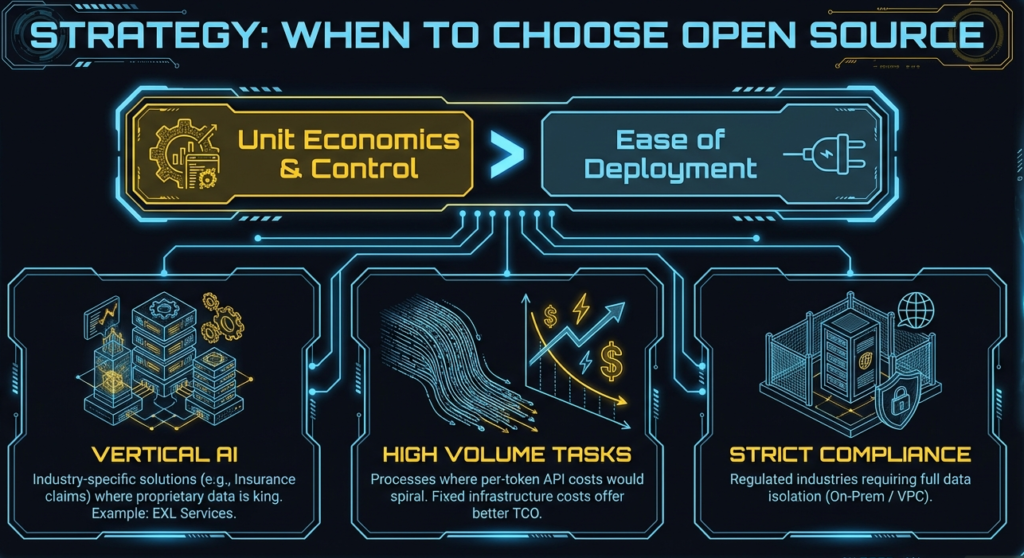
Open-source is best if you want control, transparency, and long-term ownership.
Proprietary is best if you want fast delivery, built-in support, and operational convenience.
There is no universally “best” choice. It depends on team maturity, goals, and risk tolerance.
👉 In the next section we’ll go deeper into which choice scales better once your ML systems are live and mission critical.
What happens when your ML system actually succeeds and scales?
Here is the moment most teams never plan for.
The model works.
Traffic grows.
Costs spike.
Failures suddenly matter 😬
This is where open-source vs proprietary ML frameworks stop feeling equal.
Scaling pain points with open-source frameworks
Short answer first.
Open-source scales well if your team scales too.
Open-source ML stacks demand real engineering muscle.
You manage compute.
You tune GPUs.
You design pipelines.
You own monitoring.
You fix failures at 3 AM.
That sounds scary, but it is honest.
From my own experience and deep dives on Stack Overflow and Reddit threads, teams hit the same walls again and again.
- Model drift detection needs custom logic
- Logging pipelines break under load
- Retraining jobs collide with production traffic
- Infra bills grow without guardrails
Engineers often mention that PyTorch and TensorFlow scale fine, but the surrounding MLOps tooling creates friction.
This matches what Google Brain and Meta engineers publicly share in talks and papers about internal ML platforms.
The frameworks work.
The platform work is hard.
If your team lacks DevOps depth, scaling open-source hurts.
If your team enjoys control and systems thinking, open-source feels powerful 💪
Scaling with proprietary frameworks
Direct answer.
Proprietary frameworks reduce scaling stress.
Managed ML platforms handle:
- Auto scaling
- Job orchestration
- Monitoring
- Retraining schedules
That is not marketing talk.
AWS SageMaker and Google Vertex AI teams openly publish architecture blogs showing how managed pipelines remove operational load.
I used a managed ML service during a product launch.
Traffic spiked overnight.
The system survived.
No tuning.
No manual fixes.
That felt great 😄
But later came the bill.
Scaling convenience trades predictability for usage based pricing.
That risk grows as success grows.
So the real scaling trade looks like this.
- Open-source gives cost control and technical control
- Proprietary gives operational safety and speed
Both scale.
They scale differently.
Who controls your data, models, and decisions?
Control sits with whoever owns the stack.

Data ownership in open-source ML stacks
Open-source means your data stays where you place it.
You choose storage.
You choose encryption.
You choose access policies.
That matters for:
- Healthcare
- Finance
- Government
- Enterprises with compliance audits
Regulators ask simple questions.
Where does data live?
Who accessed it?
How do models use it?
Open-source lets you answer clearly.
This matches guidance from EU AI Act drafts and NIST ML risk frameworks which stress transparency and traceability.
I have personally seen compliance reviews go smoother with open-source pipelines.
Auditors like clarity.
Open-source gives clarity.
Data and model control in proprietary platforms
Proprietary platforms abstract control.
They store metadata.
They manage pipelines.
They often move data across internal services.
That creates blind spots.
Most platforms provide compliance docs.
Few give deep visibility.
Teams on Quora and enterprise forums often complain about unclear model lineage during audits.
Vendors help.
But you still trust their system.
That trust works until regulators ask uncomfortable questions.
So the rule is simple.
High compliance needs prefer open-source.
Low compliance needs tolerate proprietary tools.

How does this choice affect hiring, teams, and future talent?
This part gets ignored a lot.
It should not.
Hiring advantages of open-source frameworks
Short answer.
Open-source skills transfer everywhere.
PyTorch experience matters across companies.
TensorFlow knowledge travels.
Kubernetes skills compound.
Engineers love that.
They join faster.
They stay longer.
From hiring discussions and my own experience screening candidates, open-source backgrounds signal adaptability.
This aligns with Stack Overflow developer surveys showing open-source tools dominate ML workflows.
Hiring feels easier.
Training feels cheaper.
Hiring risks with proprietary ecosystems
Proprietary skills age fast.
They lock people into one vendor.
Engineers worry about that.
Some avoid such roles entirely.
I saw this firsthand.
Candidates hesitated when they heard the stack relied heavily on vendor specific tooling.
They feared skill stagnation.
That fear is real.
So if talent matters long-term, open-source wins again.
| Hiring factor | Open-source ML | Proprietary ML |
|---|---|---|
| Skill portability | High | Low |
| Talent availability | Large global pool | Smaller niche pool |
| Learning curve | Steep but reusable | Easy but vendor specific |
| Engineer preference | Generally preferred | Often avoided long-term |
| Retention risk | Lower | Higher |
Which option is safer for non ML first businesses?
Direct answer.
Proprietary frameworks feel safer early.
When open-source becomes overkill
Open-source fails teams that:
- Ship fast experiments
- Have tiny engineering teams
- Do not plan long-term ML investment
I watched startups burn months building infra instead of validating products.
That hurt.
They needed outcomes, not architecture.
When proprietary frameworks fit better
Proprietary tools suit teams that want:
- Quick experiments
- Managed reliability
- Minimal infra work
Revenue focused teams benefit here.
Speed beats purity.
That is practical wisdom, not ideology.
Can you mix open-source and proprietary ML frameworks safely?
Yes.
Most strong teams do.
Hybrid stacks that work well
Successful hybrid stacks follow one rule.
Keep models portable.
Use open-source frameworks for training.
Use proprietary platforms for orchestration.
This pattern appears often in enterprise case studies published by cloud vendors themselves.
It balances control and convenience.
I like this approach.
It reduces regret later.
Hybrid stacks that fail quietly
Failures happen when teams:
- Depend on vendor specific model formats
- Tie pipelines deeply into proprietary services
Migration becomes painful.
Exit costs explode.
Teams complain about this constantly on Reddit.
So the boundary matters.
What do most comparison articles get completely wrong?
Here is my blunt take.
They focus on cost charts.
They ignore exit strategies.
They ignore team psychology.
They ignore audits.
They ignore long-term dependency.
Those mistakes lead to regret.
Real decisions happen over years, not quarters.
How should founders, CTOs, and product leaders decide step by step?
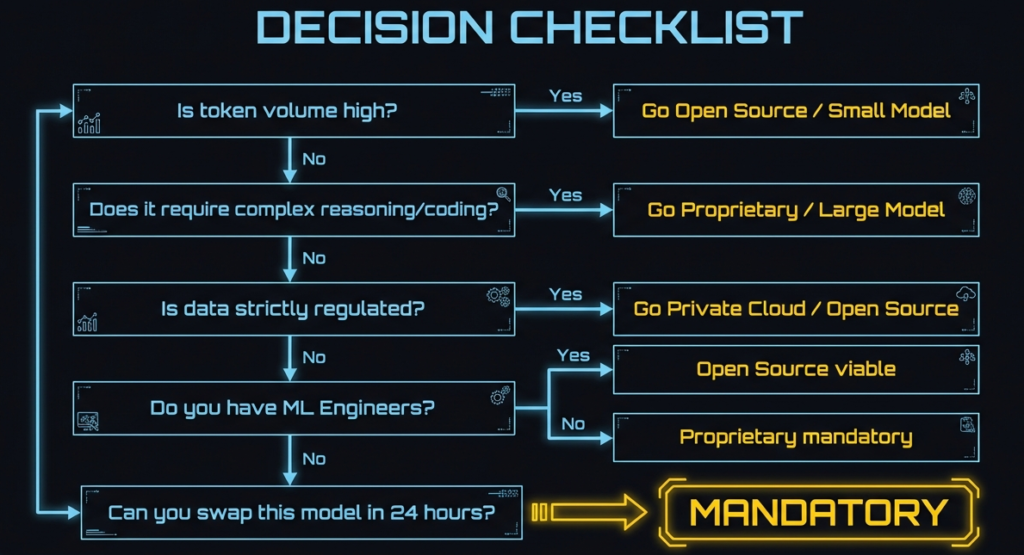
Tiny answers first.
- Speed matters most
Pick proprietary - Control matters most
Pick open-source - ML differentiates your product
Pick open-source - ML supports your product
Pick proprietary
Now the deeper logic.
Ask these questions honestly.
- Do we want to own this forever?
- Can we support this at scale?
- Can we exit this choice easily?
Your answers decide the framework.
Open-source vs proprietary ML frameworks final verdict
There is no universal winner.
There is only alignment.
Open-source gives ownership and freedom.
Proprietary gives speed and safety.
Smart teams plan exits.
They avoid emotional choices.
They think long-term.
That mindset wins.
FAQs
Is open-source ML always better than proprietary frameworks?
No.
Open-source suits teams that want control and transparency.
Do proprietary ML frameworks lock you in permanently?
They increase exit cost.
They do not make exit impossible.
Can startups start proprietary and switch later?
Yes.
They must keep models portable.
Which option fits regulated industries best?
Open-source fits better.
Auditors demand visibility.
What is the biggest hidden cost in open-source ML?
Engineering time.
Infra ownership.
What is the biggest risk of proprietary ML platforms?
Vendor dependency.
Pricing uncertainty.