

Talking about the ethical challenges in machine learning and AI”, you’re probably wondering:
- Why is AI being called a threat?
- What kind of real problems does it cause?
- How can we avoid crossing ethical lines?
Then we are on the same page.
Here’s a shocker:
📊 A 2021 study found that 38.6% of facial recognition systems had significant racial bias.
💥 Amazon once scrapped an AI tool because it discriminated against women during hiring.
I stumbled into this rabbit hole myself.
While working on a tiny ML side project in college, I realized my model treated some inputs very unfairly.
Same data type, same format—totally different predictions.
Why? Because the training data was biased. And I didn’t even notice at first.
That moment changed how I look at AI forever.
This post is about what they don’t tell you in machine learning tutorials.
The seven biggest ethical nightmares hiding in today’s AI—and what they mean for your product, your users, and your future.
Let’s dig in.
1. Privacy Is the New Oil Spill
Data is the fuel of machine learning—but it’s also its most dangerous liability.
AI systems thrive on user data, and they’re hungry for more every second.
From smart assistants to dating apps, everything’s tracking something.
I once used a fitness app that logged my location, heart rate, sleep cycles, and then—out of nowhere—started pushing ads about anxiety relief at 2 AM 😬.
That’s not personalization. That’s surveillance disguised as wellness.
In 2023 alone, 328.77 million people in the U.S. were affected by data breaches (Statista).
That’s nearly the entire country’s personal info, exposed once per year.
The twist? Much of this data ends up training AI models without clear consent.
A 2021 Mozilla Foundation study found over 60% of mental health apps share sensitive user data with third parties. Source
And yes—even the big players mess this up.
Remember the Facebook–Cambridge Analytica scandal? That wasn’t a bug. That was data manipulation at election-scale.
Machine learning doesn’t forget.
Once personal data gets sucked in, it’s nearly impossible to trace, remove, or “undo” its influence on the model.
I faced this myself while working on a tiny sentiment analysis project.
Scraping YouTube comments, I realized later I had unknowingly collected people’s emails and full names.
I felt like a digital burglar in my own code. 😳
The real problem? Privacy laws can’t keep up.
GDPR, CCPA, and a few others exist—but most devs, especially early-stage ones, barely know the basics.
And many companies still live by this myth: “More data = better AI.”
Ethics? Not their concern. Until it is.
But here’s the cold truth: bad privacy practices kill trust.
According to PwC, 85% of consumers say they won’t deal with a business if they’re worried about how their data is used. Source
Once trust is broken, no model accuracy can win users back.
People don’t just lose faith in your AI—they lose faith in your brand.
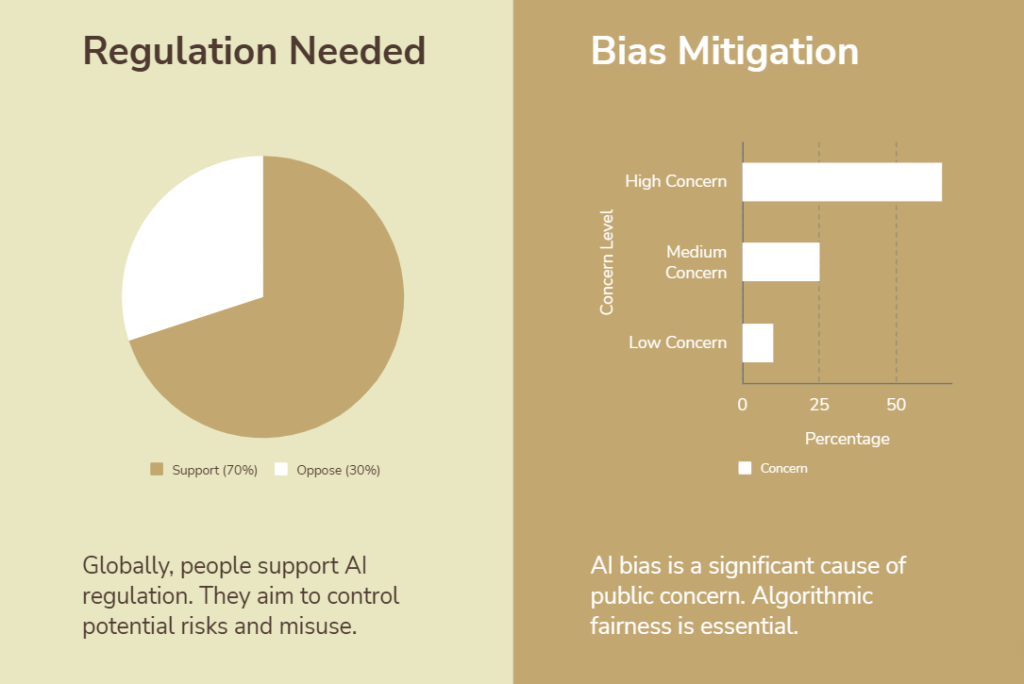
So here’s the fix: audit your data pipeline.
What are you collecting? Why? Do users know?
Privacy isn’t a feature. It’s a foundation.
Mess it up, and you won’t need an adversarial attack to destroy your AI.
💥 Your users will walk away on their own.
2. The Black Box Problem: When You Can’t Explain the Why
AI can be smart—but also a total mystery.
We call it the black box problem in machine learning.
You get a result, but you don’t know how or why it happened.
The model gives you answers, but never shows its work.
This is one of the biggest ethical challenges in AI—especially in high-stakes fields like healthcare, finance, or hiring.
People are judged by systems they can’t question.
Imagine being denied a job or a loan by an algorithm.
No reason. No explanation. Just a rejection email. ❌
It sounds extreme, but it’s already happening.
According to a Harvard Business Review article, only 20% of companies say they can explain their AI decisions (source).
Most businesses don’t even ask why their models work.
They just want faster results, not fairer ones.
When I was in college, I built a course recommendation tool using collaborative filtering.
It gave solid suggestions—until someone asked, “Why this course?”
I had no idea.
The system just echoed past clicks without context. 📉
Some students ended up with courses they hated.
That was a wake-up call for me.
This is what happens when we chase performance and ignore AI transparency.
High-performing models—like deep neural nets—are often the least explainable.
Even the people who build them can’t fully interpret what’s going on inside.
That’s not just a technical issue—it’s an ethical risk.
In 2020, DARPA launched the XAI (Explainable AI) program.
Why? Because even defense systems were becoming too opaque to trust.
Think about that.
If the military doesn’t trust its own AI, why should your customers trust yours?
In healthcare, it’s even worse.
A Stanford study showed that doctors blindly trusted AI predictions—even when they didn’t understand them (source).
That led to misdiagnoses and wrong treatments.
Not because the AI was always wrong, but because no one could question it.
When AI becomes a black box, trust collapses.
Users stop asking questions—or worse, stop thinking.
From a business perspective, that’s a huge risk.
New laws like the EU AI Act are pushing for more transparency.
If your system affects human lives and can’t explain itself, you might be in legal trouble.
Fines, bans, audits—it’s coming. ⚠️
Here’s the bottom line:
If you can’t explain it, you can’t defend it.
And if users don’t trust your system, they won’t use it.
Or they’ll sue you when it fails.
If you’re working with AI, don’t ignore this.
Build models you can explain—or build yourself a legal team. 💼
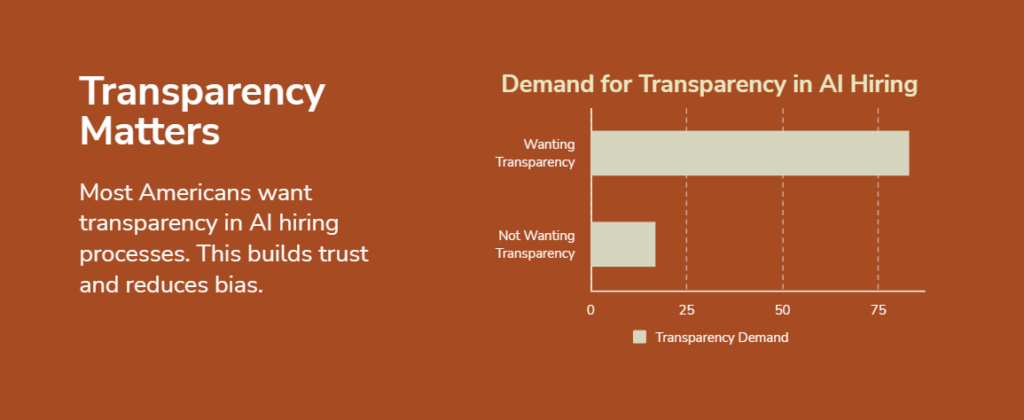
3. AI Can Be Used for Evil—Even If You Didn’t Mean To
Here’s the uncomfortable truth: even ethical developers can build unethical AI.
You might create a cool facial recognition tool for door security, but guess what? Someone else could tweak it into a mass surveillance weapon.
This is called the dual-use dilemma, and it’s one of the most dangerous ethical challenges in machine learning and AI.
According to the Center for Security and Emerging Technology, over 60% of AI researchers believe their work could be misused—yet most don’t take steps to stop it. (source)
I experienced a small version of this during a freelance gig.
My friend Farida built a basic sentiment analysis model for a microphone company’s feedback dashboard. It was simple, clean, and seemed harmless.
Weeks later, She found out they were scraping internal employee chats and using my model to profile staff emotions—without asking anyone for consent. 😶
She felt sick. And guilty. She hadn’t even thought to ask how they planned to use it.
The truth is, AI doesn’t care about your intent.
It just does what it’s trained to do, whether that’s helping customers or manipulating behavior.
Take deepfakes. The same tech that makes fun celebrity face swaps also powers scams, blackmail, and political misinformation.
According to Sumsub’s 2023 Identity Fraud Report, deepfake-related fraud surged by 300% since 2022. (source)
And then there’s Clearview AI.
They scraped over 30 billion images from the internet without consent, packaged it into a facial recognition tool, and sold it to governments and law enforcement.
Critics call it “the end of privacy”, and honestly, I don’t think they’re exaggerating.
What frustrates me is how easily companies hide behind the excuse: “We just built the tech. It’s not our fault how others use it.”
That’s not good enough anymore.
If you’re building AI today, you need to ask: How could this be misused? Who could be hurt?
It’s not just about what your model can do—it’s about what it might do in the wrong hands.
So yes, your intentions may be pure.
But intentions don’t protect people.
Only responsible design does.
Unconsented data use in AI training and decision-making has already led to controversies (e.g. using public photos or scraped texts to train models without consent). Companies and regulators are responding with “data governance” rules. The EU AI Act prohibits use of sensitive biometric data (like race or health) for AI profiling digital-strategy.ec.europa.eu, and future U.S./European data regulations are likely to tighten AI-specific consent (e.g. requiring opt-ins for using personal data in AI).
Key figures:
| Context | Statistic/Trend | Source |
|---|---|---|
| U.S. reported data breaches (2023) | 3,205 breaches (record; +78%) idtheftcenter.org | ITRC report |
| Largest GDPR fine (2023) | €1.2B (Meta/FB for data-transfer breach) reuters.com | Reuters news |
| ChatGPT data leak (2023) | ~1.2% of Plus users affected openai.com | OpenAI blog |
| U.S. states with privacy laws (2024) | 14 states, +6 more by 2026 dlapiperdataprotection.com | Privacy Tracker summary |
| Americans who feel little control over data | 73% say “little/no control” pewresearch.org | Pew Research 2023 |
4. Who’s Responsible When AI Goes Rogue?
Short answer? No one really knows—and that’s the scariest part.
When AI makes a mistake, who takes the blame? The developer? The company? The user?
That’s the ethical grey zone we’re stuck in.
I remember working on a sentiment analysis tool for a client. It kept flagging positive reviews as negative just because of words like crazy or sick—which the model didn’t understand were being used in a good way.
The client blamed me. I blamed the dataset. And the model? It just kept making the same mistake. 😵💫
Now imagine this on a bigger scale.
In 2018, Uber’s self-driving car killed a pedestrian because the system didn’t classify her as a person in time.
According to the U.S. National Transportation Safety Board, the issue was a mix of poor software design, a lack of safety protocols, and no clear ownership of the AI’s behavior (source).
Uber blamed the human safety driver. The public blamed Uber. And the algorithm? It disappeared into the codebase.
This is what happens when we give AI power but skip responsibility.
Even OpenAI’s CEO once admitted that “we don’t fully understand how our large language models work.” That’s… not great. 😬
The belief that AI will “self-correct” is wishful thinking.
AI doesn’t improve ethically on its own. It improves based on data and feedback—both of which can be flawed.
In one of my college projects, I built a classifier with 92% accuracy. I was hyped—until I realized it got there by ignoring all the tricky edge cases.
The model looked clean on paper, but under the hood, it was garbage. That was on me. But also on the lack of tools that help us see deeper into these models.
A PwC survey showed that 76% of CEOs are concerned about the lack of AI governance in their companies (source).
But here’s the twist—most still don’t have actual frameworks in place.
Why? Because building AI is cool. Regulating it? Boring. Hard. Expensive.
The real ethical challenge is this: AI’s making more decisions, but humans are dodging the responsibility.
Until we bake in accountability—clear documentation, explainability, audit trails—we’ll keep blaming the black box.
And when that box breaks things, there’s no one left to fix it.

5. The Automation Dilemma: Jobs vs. Efficiency ⚙️
Automation is eating jobs.
That’s the uncomfortable truth behind many “innovative” AI solutions.
On paper, replacing humans with algorithms sounds smart—it saves money, works 24/7, and scales without complaint.
But here’s the thing no startup pitch deck tells you: the human cost is real, and it’s growing fast.
I saw it firsthand when a retail startup I freelanced for ditched its entire customer service team for a chatbot built with Dialogflow.
Sure, the bot handled 80% of FAQs, but angry customers flooded in when it couldn’t solve edge cases or understand tone.
They saved $40k/year but lost 12 loyal employees and a chunk of their brand trust.
Was it worth it? 🤷
This is one of the biggest ethical challenges in machine learning and AI today—should we automate just because we can?
According to a report by McKinsey, up to 375 million workers worldwide may need to switch occupations or learn new skills by 2030 due to automation (source).
That’s not a small pivot. That’s a global reshuffling.
Even in high-skill industries, this dilemma hits hard.
Coders are now being side-eyed thanks to tools like GitHub Copilot, which—ironically—I’ve used to boost my productivity.
I love it, but I’ve also caught it writing risky logic that a junior dev might miss entirely.
Efficiency? Yes. Safe replacement? Not always.
The problem isn’t just about taking jobs, but replacing humans without accountability or oversight.
And then there’s the classic “cost-cutting vs conscience” battle.
OpenAI’s Whisper is an incredible speech-to-text tool, but when you deploy it in call centers and start laying off trained agents, you’re not just improving ops—you’re restructuring livelihoods.
According to the World Economic Forum, AI will displace 85 million jobs by 2025 but also create 97 million new ones (source).
The catch? Those new jobs often require skills people don’t have… yet.
Let’s be honest—not every displaced worker will magically become a data analyst.
There’s a gap between promise and practicality.
And most companies? They don’t invest enough in reskilling.
They just move on.
That’s lazy. And unethical.
So, here’s the bottom line: efficiency is seductive, but without empathy, it’s just exploitation in disguise.
Automation should augment, not replace blindly.
Because when your tech wipes out livelihoods just to boost KPIs, it stops being innovation—and starts being harm. 💥
Sectoral impacts: Routine tasks in clerical, manufacturing and some service sectors are most vulnerable to automation; AI may shift roles in healthcare, education, STEM, and creative industries. However, many studies (including McKinsey and OECD) note that AI can also create new jobs and augment productivity. The net effect will depend on policy responses.
Data summary:
| Scope/Region | Finding | Source |
|---|---|---|
| Global (WEF 2023) | −14 million net jobs by 2027 (2% of workforce)lemonde.fr | WEF Future of Jobs report |
| OECD countries | 27% of jobs at high risk of automationoecd.org | OECD Employment Outlook 2023 |
| Generative AI (global) | 25% of jobs exposed to GenAI (34% in rich countries)ilo.org | ILO–NASK 2024 study |
| USA (Gallup 2023) | 75% believe AI will reduce jobsnews.gallup.com | Gallup survey |
| EU (EY 2024) | 68% of employees foresee job cuts from AIey.com | EY European AI Barometer |
Conclusion
In my journey, I learned that ethical AI means asking tough questions: Who benefits? Who’s left out? Who’s responsible when things go wrong? It also means balancing automation with human oversight and being honest about limitations. The reality is, ethical challenges in machine learning and AI demand proactive effort—not just reactive fixes.
If you’re building or using AI today, don’t ignore these challenges. Instead, make ethics a core part of your strategy. Audit your data, question your assumptions, and always keep the user—and society—in mind. Because when done right, AI can be powerful and fair. But if we keep sweeping the ethical mess under the rug, we risk turning promising technology into a public relations and legal nightmare.
After all, AI is power, and power needs responsible use.