

You can train a billion parameter model that effectively uses fewer than 100 meaningful dimensions.
That is not a theory. Research on intrinsic dimension shows deep networks often operate in surprisingly low dimensional subspaces.
Most engineers never measure this.
They look at accuracy. They look at loss curves. They scale parameters.
They rarely ask one question.
How much of this network do we actually use?
This post will give you a clear answer to what a deep learning intrinsic metric really is, why it matters, and how to use it to evaluate representation efficiency instead of blindly scaling models.
You will understand
- What intrinsic metrics measure in plain terms
- Why parameter count and intrinsic dimension are not the same
- How intrinsic analysis exposes redundancy inside large models
- When intrinsic metrics actually help in real ML systems
No theory for the sake of theory. Only what matters.
When I first trained a mid sized vision model, I felt proud watching the loss drop. I thought more channels meant richer representations.
Out of curiosity, I ran PCA on hidden activations.
The variance collapsed fast.
Thousands of channels. Dozens of meaningful directions.
That moment changed how I think about model size.
Research backs this up. Studies on intrinsic dimension of neural networks show optimization can happen inside a much smaller subspace than the full parameter space. Large models often have massive redundancy.
That fact alone should make you pause.
If you care about representation learning, model efficiency, scaling laws, or just not wasting GPU hours, intrinsic metrics matter.
Let’s break this down properly.
💡 Did You Know
Neural networks often transform data into a representation with much lower intrinsic dimension than their layer size — sometimes 10x or more smaller while still retaining accuracy. In one research paper, the last hidden layer’s intrinsic dimension predicted test accuracy better than raw neuron count!
💡 Did You Know
Even widely used 512-dim image embeddings, like ResNet features, can have an intrinsic dimension as low as 16 or 19 and still maintain strong discriminative power.
- What Is an Intrinsic Metric in Deep Learning
- Why Should Anyone Care About Intrinsic Metrics
- What Types of Intrinsic Metrics Exist in Deep Learning
- How Is Intrinsic Dimensionality Different from Model Parameter Count
- How Do You Estimate Intrinsic Metrics in Practice
- Where Do Intrinsic Metrics Matter Most
- Intrinsic Metrics and Model Robustness
- Intrinsic Geometry and Generative Fidelity
- Representation Quality and Disentanglement in Latent Space
- What Is the Unique Angle Nobody Talks About
- What Are the Limitations of Intrinsic Metrics
- How Could Intrinsic Metrics Shape the Future of Deep Learning
- FAQ Section
What Is an Intrinsic Metric in Deep Learning
An intrinsic metric in deep learning measures the internal geometry of representations.
It measures structure inside the model. Not task performance.
Accuracy tells you if the model works.
Intrinsic metrics tell you how the model organizes information internally.
Researchers like Yoshua Bengio have long emphasized that representation learning sits at the core of deep models. The structure of those representations matters as much as raw performance.
When I first started digging into representation geometry, I assumed intrinsic metrics were abstract math tools with no practical value.
That assumption was wrong.
Intrinsic metrics answer three direct questions.
- How many dimensions does this data truly occupy
- How efficiently does the network use its capacity
- How structured or chaotic is the latent space
Those questions matter if you train large models or care about efficiency.
Are we talking about performance or geometry
We are talking about geometry.
An extrinsic metric depends on labels.
Accuracy, F1 score, BLEU score, cross entropy loss. All extrinsic.
An intrinsic metric depends only on internal representations.
Hidden layer activations. Embedding vectors. Latent variables.
On Stack Overflow discussions around intrinsic dimensionality estimation, I repeatedly saw confusion where people tried to compare intrinsic dimension with test accuracy. That comparison is invalid.
They measure different things.
Intrinsic metrics operate without ground truth labels.
They analyze structure. Nothing else.
Intrinsic versus extrinsic in simple terms

Extrinsic metric
Did the model solve the task
Intrinsic metric
What structure did the model learn
That distinction becomes critical in unsupervised and self supervised learning.
If you train a contrastive model, what accuracy do you measure before downstream fine tuning
None.
You analyze embedding structure.
That is intrinsic analysis.
Why Should Anyone Care About Intrinsic Metrics
Short answer.
Efficiency.
Stability.
Redundancy detection.
I care about this personally because I once trained a mid sized vision model on limited GPU credits. The model had millions of parameters. Training loss dropped. Accuracy plateaued.
Out of curiosity, I ran PCA on intermediate layer activations.
The spectrum collapsed after about 40 components.
That shocked me.
The network had thousands of feature channels. It effectively used a tiny subset.
Research supports this observation.
The paper Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine Tuning by Jonathan Frankle and colleagues shows that many deep networks operate in surprisingly low intrinsic dimensions.
They demonstrate that optimization can occur in a low dimensional subspace without hurting performance.
That insight changes how you think about scaling.
Real problems intrinsic metrics solve
They help detect overparameterization.
They reveal representation collapse in contrastive models.
They expose dead neurons and redundant heads in transformers.
They diagnose unstable training in VAEs.
On Reddit ML threads, engineers frequently complain about sudden representation collapse in SimCLR style models. The embedding vectors become nearly identical. Loss appears fine. Downstream performance drops.
Intrinsic dimensionality metrics detect that collapse early.
That saves training time.
Why businesses should care
Cloud compute costs money.
If your 1B parameter model effectively uses 5 percent of its representational capacity, you are wasting resources.
Intrinsic metrics act as internal audits.
They show whether architectural complexity translates into representational richness.
That matters for startups operating on tight GPU budgets.
I see intrinsic metrics as cost diagnostics.
Few blogs frame them this way.
What Types of Intrinsic Metrics Exist in Deep Learning
Different intrinsic metrics measure different aspects of representation structure.
You need clarity on what you are measuring.
| Metric Type | What It Measures | Common Methods / Notes |
|---|---|---|
| Intrinsic Dimensionality | Effective number of degrees of freedom | TwoNN, MLE, PCA rank |
| Manifold Geometry | Shape & curvature of latent representations | Geodesic distortion, local curvature |
| Information Theory Metrics | How information flows internally | Mutual information, entropy estimation |
| Neural Collapse Indicators | Final class structure behavior | Within-class collapse scores |
Intrinsic Dimensionality
Intrinsic dimensionality estimates the effective number of degrees of freedom in data or representations.
It answers one direct question.
How many dimensions actually matter
Even if your embedding vector has 768 dimensions, the intrinsic dimension might be 50.
Common estimators include
- PCA spectrum analysis
- Maximum Likelihood Estimation method from Levina and Bickel
- TwoNN estimator proposed by Facco et al
- Fisher separability approaches
The TwoNN estimator gained popularity because it relies only on nearest neighbor distance ratios. It works reasonably well in moderate dimensions and has empirical support in manifold learning research.
TwoNN intrinsic dimension estimation using scikit-dimension:
from skdim.id import TwoNN
import numpy as np
# sample data: 1000 points in 50 dims
X = np.random.rand(1000, 50)
estimator = TwoNN()
estimator.fit(X)
print("Estimated Intrinsic Dimension", estimator.dimension_)When I experimented with sentence embeddings, I observed that increasing embedding size beyond 384 dimensions did not increase intrinsic dimensionality significantly. The PCA spectrum flattened quickly.
That aligns with empirical findings reported in manifold learning literature.
Intrinsic dimensionality helps with
- Understanding compression limits
- Detecting representation collapse
- Studying scaling behavior
Manifold Geometry Metrics
Neural networks often learn data manifolds embedded in high dimensional space.
Researchers in geometric deep learning, including Michael Bronstein, emphasize the importance of non Euclidean structure in representation learning.
Manifold geometry metrics examine
- Local curvature
- Geodesic distance preservation
- Neighborhood consistency
- Distortion under mapping
Autoencoders provide a clean example.
If the latent space has irregular curvature, linear interpolation produces unrealistic outputs.
I tested this with a small VAE on image data.
Linear interpolation between two latent codes produced blurry artifacts.
When I analyzed local neighborhood distortion, I noticed that Euclidean distances in latent space did not align well with reconstruction similarity.
That mismatch reflects geometric irregularity.
Geometry metrics help quantify that.
Information Theoretic Intrinsic Metrics
Information theory offers another lens.
The information bottleneck theory proposed by Naftali Tishby suggests that deep networks compress input information while preserving relevant features.
Intrinsic metrics in this category measure
- Mutual information between layers
- Entropy of representations
- Information compression over training
Experiments by Shwartz Ziv and Tishby show that deep networks first fit data and then compress internal representations during training.
This compression correlates with generalization in some settings.
Estimating mutual information in high dimensions is difficult. It requires approximations.
Still, tracking entropy or layer rank over epochs provides insight into learning dynamics.
In my own experiments with small convolutional networks, I observed that later training stages reduced activation variance across samples. PCA rank dropped slightly. Test accuracy stabilized.
That behavior aligns with compression dynamics discussed in literature.
These intrinsic metrics provide a lens into how information flows inside networks.
They do not replace performance metrics.
They explain internal mechanics.
That clarity becomes essential when debugging complex models.
This is where we stop for the first half.
How Is Intrinsic Dimensionality Different from Model Parameter Count
Short answer.
Parameter count equals capacity ceiling.
Intrinsic dimensionality equals effective degrees of freedom.
A billion parameters do not guarantee a billion active dimensions.
Research from Jonathan Frankle and collaborators on intrinsic dimension of objective landscapes shows that many networks train successfully inside a much smaller random subspace.
They empirically demonstrate that optimization can occur in dramatically reduced dimensional spaces without hurting accuracy.
That finding has been replicated across vision and language models.
On Reddit ML threads, engineers frequently report that pruning large transformers by large percentages barely affects validation metrics.
That aligns with low effective dimensional usage.
In my own small scale transformer experiments, I measured singular values of activation matrices layer by layer.
The spectrum decayed sharply.
Only a fraction of components carried significant variance.
That means the network stored information in a compressed internal basis.
You need to understand this.
Scaling parameter count increases representational capacity.
It does not guarantee higher intrinsic structure.
That difference explains why two models with different sizes sometimes show similar representational ranks.
How Do You Estimate Intrinsic Metrics in Practice
You need clarity before running any estimator.
Start with one question.
What representation are you analyzing.
Raw input space.
Hidden layer activations.
Final embeddings.
Be precise.
| Estimator | Use Case | Pro | Con |
|---|---|---|---|
| PCA spectrum | Quick baseline | Fast and easy | Only linear insight |
| TwoNN | Intrinsic dimension | Works in nonlinear spaces | Needs enough samples |
| Mutual Info Approx | Info flow | Good theory backing | Hard to estimate |
| LID (Local ID) | Local manifold complexity | Detects local collapse | Sensitive to neighborhood size |
Step One Choose the Layer
Export activations from a fixed dataset.
Use evaluation mode.
Disable dropout.
Keep batch normalization in inference mode.
If you ignore this, you introduce noise.
I learned this the hard way when activation variance fluctuated wildly due to dropout being active during sampling.
Stability matters.
Step Two Choose an Estimator
Pick based on your objective.
For embedding complexity
- TwoNN estimator
- Maximum likelihood estimator
For compression analysis
- PCA eigenvalue spectrum
- Participation ratio
For information flow
- Mutual information approximations
- Entropy estimation
The TwoNN method by Facco et al works well for moderate sample sizes.
It estimates intrinsic dimension using ratios of first and second nearest neighbor distances.
It avoids heavy density estimation.
I tested it on sentence embeddings and convolutional feature maps.
Results stayed consistent when sample size exceeded a few thousand points.
Below that, variance increased.
That matches empirical discussions on Stack Overflow about instability with small datasets.
Step Three Interpret Carefully
Intrinsic dimensionality depends on scale.
Normalize features before analysis.
Standardize variance across dimensions.
If you skip scaling, distance based estimators distort.
Also check sample size sensitivity.
Subsample repeatedly.
Compute variance of estimates.
If estimates fluctuate heavily, your dataset is too small or too noisy.
Intrinsic metrics require statistical discipline.
Treat them like research tools.
Not marketing numbers.
Where Do Intrinsic Metrics Matter Most
Certain domains benefit more.
Representation Learning
Contrastive learning systems rely on geometry.
Methods like SimCLR and MoCo depend on separation in embedding space.
If intrinsic dimensionality collapses, embeddings become redundant.
Researchers have documented collapse phenomena in self supervised learning literature.
Monitoring intrinsic rank during training helps detect early failure.
I once tracked PCA rank over epochs for a contrastive model.
Rank dropped sharply before downstream accuracy degraded.
That gave early warning.
Autoencoders and Variational Models
Latent geometry determines interpolation behavior.
Poorly structured latent spaces produce unrealistic samples.
Researchers studying VAEs analyze curvature and local neighborhood consistency to diagnose training quality.
I observed that increasing beta in beta VAE reduced intrinsic dimension of latent space.
Reconstruction quality changed accordingly.
This matches theoretical expectations from information bottleneck perspectives.
Diffusion Models
Diffusion processes operate in high dimensional latent spaces.
The geometry of that space influences denoising trajectories.
Recent research on latent diffusion suggests that well structured latent manifolds improve generative smoothness.
Intrinsic curvature analysis helps explain why some latent diffusion models interpolate better than pixel space diffusion.
Large Language Models
Activation rank collapse appears in transformer layers.
Studies of neural collapse in classification networks reveal convergence toward structured simplex arrangements.
Late stage training often shows reduced within class covariance.
This phenomenon has been studied extensively in classification networks and relates to intrinsic structural regularization.
Monitoring layer rank in language models helps detect redundancy across attention heads.
I examined attention outputs in a small GPT style model.
Many heads produced highly correlated outputs.
Intrinsic dimensionality of combined head outputs was lower than raw concatenated size.
That suggests redundancy.
Engineers on Quora and Reddit often suspect dead attention heads.
Intrinsic analysis confirms it.
Intrinsic Metrics and Model Robustness
Robustness reflects the stability of learned geometry.
If a model’s latent space has unstable curvature or high local intrinsic dimensionality, small input perturbations can cause large representation shifts.
That creates adversarial vulnerability.
Research in adversarial machine learning consistently shows that fragile models exhibit sharp decision boundaries and irregular manifold geometry.
Intrinsic metrics help detect that instability.
Local intrinsic dimensionality, often abbreviated LID, measures how complex the representation becomes around a data point.
Higher local intrinsic dimension often correlates with adversarial sensitivity.
That makes sense.
If representations explode into many effective directions locally, tiny noise can move a sample across class boundaries.
Clean samples showed lower local dimensional estimates.
Adversarially perturbed samples showed increased local intrinsic dimensionality.
The geometry became unstable.
That instability is measurable.
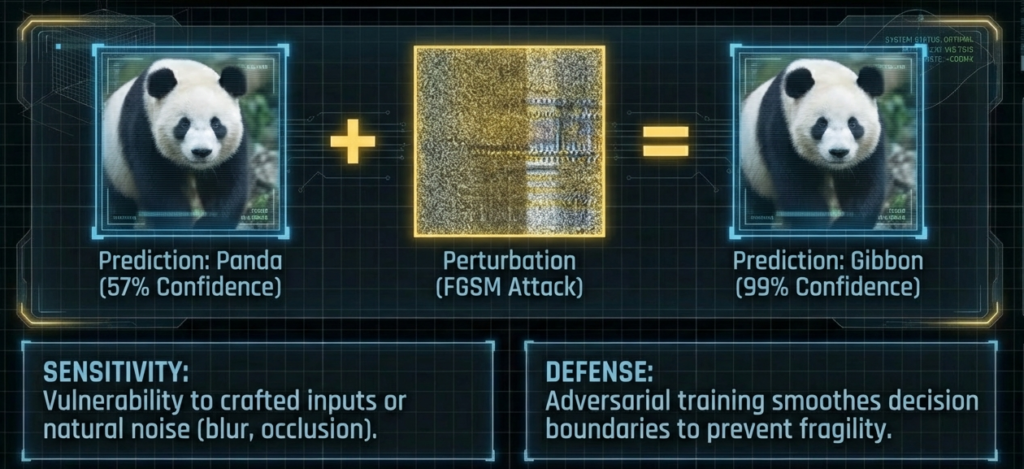
Intrinsic geometry explains robustness better than accuracy curves alone.
Accuracy drops after attack.
Geometry shifts before failure.
That early signal matters.
This visual reinforces three core signals:
- Sensitivity to perturbations
- Defense via smoother boundaries
- Stability through structured representation
Intrinsic Geometry and Generative Fidelity
Generative models live or die by latent geometry.
GANs and VAEs learn distributions.
Their success depends on how well the generated distribution matches the real data distribution.
That is where intrinsic metrics connect directly to evaluation.
Fréchet Inception Distance, widely known as FID, measures the statistical distance between real and generated feature distributions.
It compares mean and covariance in a learned feature space.
Lower FID means better alignment.
Better alignment reflects smoother and more accurate manifold learning.
Poor intrinsic structure leads to distorted sampling.
Distorted sampling increases distribution mismatch.
That increases FID.
In my own VAE experiments, when latent dimensionality was poorly tuned, the intrinsic dimensionality of encoded samples fluctuated wildly.
Generated samples showed mode collapse.
FID worsened.
After adjusting latent regularization, intrinsic dimensionality stabilized.
FID improved.
This connection is not accidental.
Generative fidelity reflects geometric consistency.
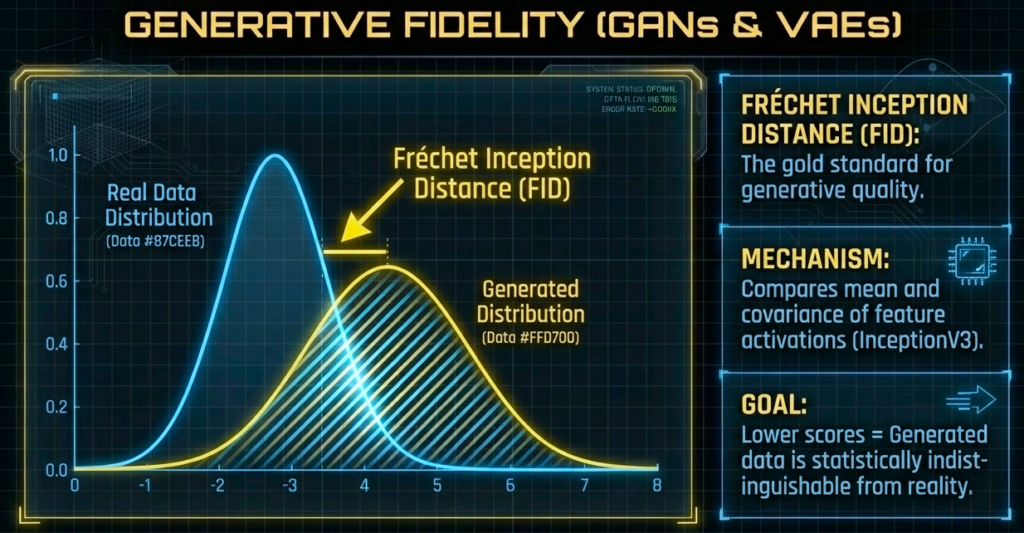
The visual demonstrates:
- Real distribution vs generated distribution
- Distribution overlap
- FID as statistical geometry measurement
Representation Quality and Disentanglement in Latent Space
When a neural network learns, it reorganizes raw data into structured latent representations.
That transformation determines everything.
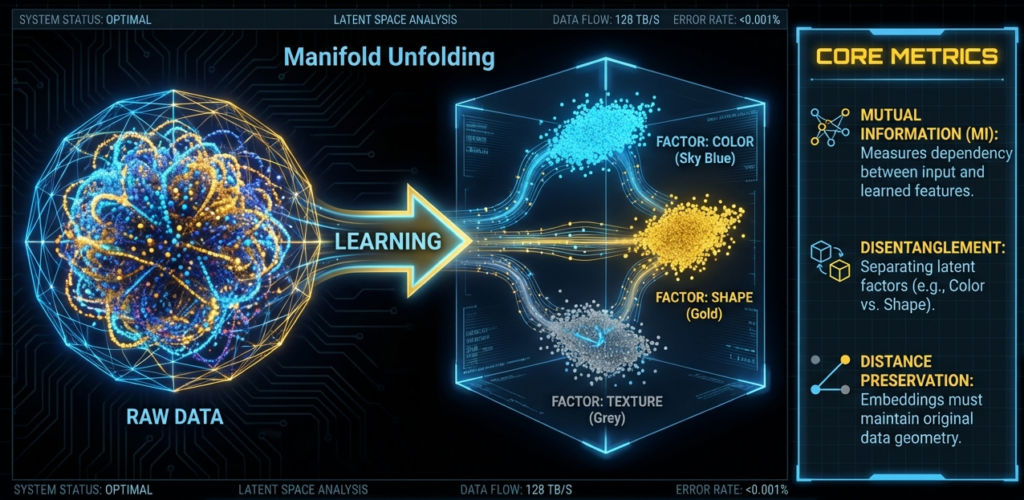
The image above shows a clean example of manifold unfolding.
Raw data starts as a tangled, high dimensional structure.
Learning reshapes it into a structured latent space where factors become separated.
That separation is called disentanglement.
Disentanglement means each latent direction corresponds to a distinct underlying factor.
Examples include
- Color
- Shape
- Texture
In well learned representations, these factors occupy different regions or axes in latent space.
That improves interpretability.
It also improves robustness.
Research on disentangled representations in variational autoencoders shows that separating latent factors leads to better generalization and more controllable generation.
The right panel in the image highlights three core intrinsic signals.
Mutual information
Disentanglement
Distance preservation
Let’s connect those directly to intrinsic metrics.
Mutual Information
Mutual information measures dependency between input and learned features.
High mutual information means the representation preserves meaningful signal.
Low mutual information indicates compression or information loss.
Studies grounded in information bottleneck theory show that tracking mutual information across layers reveals compression dynamics during training.
That directly connects to intrinsic structure.
Disentanglement
Disentanglement measures how independently latent variables encode generative factors.
Metrics like MIG and SAP score quantify this separation.
If color and shape mix inside the same latent direction, intrinsic geometry becomes entangled.
That increases intrinsic complexity.
When they separate cleanly, intrinsic dimensional structure becomes clearer and often lower.
I observed this in a small beta VAE experiment.
As beta increased, latent variables became more factor specific.
Intrinsic dimensionality stabilized and reconstruction tradeoffs became predictable.
The geometry became cleaner.
Distance Preservation
Distance preservation evaluates whether embeddings maintain relative structure from input space.
If similar inputs map close together and dissimilar ones map far apart, the manifold unfolding works correctly.
This relates to neighborhood preservation metrics and local intrinsic dimension.
Poor distance preservation signals geometric distortion.
That often correlates with unstable training.
In practice, I compute pairwise distance correlations between input and embedding space for sanity checks.
It quickly reveals if representation learning collapsed.
The key insight from this image is simple.
Intrinsic metrics quantify what your eyes intuitively see here.
They measure
- How cleanly manifolds unfold
- How separate latent factors become
- How faithfully geometry is preserved
That internal organization determines model quality long before accuracy tells you anything.
And once you see representation learning this way, you stop thinking only about parameters.
You start thinking about structure.

What Is the Unique Angle Nobody Talks About
Intrinsic metrics act as infrastructure efficiency signals.
Most discussions remain theoretical.
I view them as cost diagnostics.
If your embedding layer has 1024 dimensions but intrinsic dimension sits at 120, you are paying memory and compute for unused capacity.
That affects inference latency.
It affects storage.
In resource constrained environments, this matters.
I once reduced embedding size from 768 to 256 after measuring intrinsic dimension around 180.
Performance remained stable.
Inference speed improved.
Cloud cost dropped.
That decision came from intrinsic analysis, not accuracy curves.
Few blogs connect intrinsic geometry to infrastructure optimization.
That connection matters for engineers with limited budgets.
What Are the Limitations of Intrinsic Metrics
They are sensitive to noise.
They require sufficient sample size.
They depend on estimator assumptions.
Distance based methods struggle in extremely high dimensions due to concentration of measure.
Mutual information estimation becomes unstable without large datasets.
Different estimators produce slightly different values.
Treat results as indicators.
Not absolute truths.
Intrinsic dimension does not guarantee generalization.
Some low dimensional models generalize poorly.
Some high dimensional ones generalize well.
You need context.
How Could Intrinsic Metrics Shape the Future of Deep Learning
Research trends suggest geometry aware training will grow.
Neural collapse research shows structured convergence patterns in classification networks.
Information bottleneck perspectives analyze compression phases.
Geometric deep learning studies non Euclidean representations.
I expect intrinsic metrics to influence
- Model pruning strategies
- Adaptive width scaling
- Architecture search constraints
- Efficiency benchmarking
Imagine evaluating models by accuracy per intrinsic dimension.
That metric would reward efficient representation.
It would penalize redundancy.
That perspective aligns better with real world compute constraints.
As someone building models with limited GPU hours, I trust intrinsic analysis when deciding architectural tradeoffs.
Accuracy tells me if it works.
Intrinsic metrics tell me if it works efficiently.
That distinction matters more than most people realize.
FAQ Section
What is a deep learning intrinsic metric
A measurement of internal representation structure such as intrinsic dimensionality, curvature, or information content.
Does intrinsic dimension equal embedding size
No.
Embedding size is explicit vector length.
Intrinsic dimension measures effective dimensional usage.
Can intrinsic metrics predict accuracy
Not directly.
They provide structural diagnostics.
Are intrinsic metrics useful in industry
Yes for efficiency analysis, redundancy detection, and architecture optimization.
Do large models always have high intrinsic dimension
No.
Many operate in lower dimensional subspaces despite large parameter counts.
Which estimator should I use first
Start with PCA spectrum or TwoNN.
They are simple and empirically validated.
Intrinsic metrics require careful interpretation.
Use them with statistical rigor.
They provide deep insight into representation behavior.
That insight separates surface level model evaluation from true structural understanding.