

Your machine learning model is probably discriminating right now.
Even if accuracy looks great.
Even if nobody complained yet.
Here is a hard fact.
A 2019 Science study found a widely used healthcare algorithm underestimated the needs of Black patients by more than 50 percent compared to white patients with the same risk score.
Another MIT and Stanford study showed facial recognition systems misidentified dark skinned women up to 34 percent of the time while error rates for light skinned men stayed under 1 percent.
That gap is not a bug.
That is bias at scale 😬
Did You Know
Many facial recognition systems have error rates up to 100x higher for some demographic groups compared to others. That gap is not random it shows how deeply bias embeds in design.
I have shipped models that looked perfect in dashboards.
Clean data.
Strong metrics.
Happy stakeholders.
Then I sliced results by user groups and everything changed.
One group carried most of the errors.
Nobody noticed because nobody checked.
This post exists for that exact reason.
Let’s break it down clearly.
- What Does Bias in Machine Learning Actually Look Like
- Where Does Bias Actually Come From in Your Model
- What Does Fairness Even Mean for an Algorithm
- How Do You Actually Detect Bias in Your Model
- What Can You Actually Do to Make Your Model Fairer
- Can You Just Remove Sensitive Attributes and Call It Fair
- Who Is Responsible When a Biased Model Causes Harm
- What About the Bias We Cannot See
- How Do You Talk About Fairness With Stakeholders Who Do Not Get It
- What Is the Future of Fair AI
- Frequently Asked Questions About Bias and Fairness in ML
- Conclusion
What Does Bias in Machine Learning Actually Look Like
ML bias equals systematic unfair outcomes.
Not random errors.
Patterns that hurt the same groups again and again.
Quick answers you need to remember
- Bias hides inside good metrics
- Some groups get worse predictions
- Scale multiplies harm
- Most teams miss it completely
Bias rarely screams.
It whispers through averages.
A Stanford study showed commercial AI systems had error rates under 1 percent for light skinned men and over 30 percent for dark skinned women.
Source Gender Shades project by MIT Media Lab and Stanford researchers published via media dot mit dot edu.
That gap alone can destroy trust 😬
The resume scanner that rejected qualified women
Amazon built a resume screening model to speed up hiring.
It punished resumes that contained words like women’s chess club or women’s college.
Why it happened
- Historical resumes came mostly from men
- The model learned male patterns as success signals
- Gender correlated tokens became negative weights
The data was accurate.
The world that produced it was not fair.
Internal reviews leaked later showed the system learned to downrank candidates who deviated from historical hiring patterns.
Source Reuters report available at reuters dot com.
This is a core lesson.
Models do not learn truth.
They learn patterns that survived selection.
The healthcare algorithm that denied care to Black patients
A widely used healthcare risk algorithm in the US decided who received extra medical support.
The issue was subtle.
The model predicted future healthcare cost.
Not actual health needs.
Because Black patients historically receive less care, they generate lower costs.
The model labeled them healthier.
The result
- Sicker Black patients got less help
- White patients received more resources
Researchers found Black patients were 54 percent sicker than white patients assigned the same risk score.
Published in Science journal.
Source Science 2019 Obermeyer et al available via science dot org.
This is proxy bias in its purest form.
Where Does Bias Actually Come From in Your Model
Bias does not appear magically at deployment.
It enters at specific moments in your pipeline.
I will show you where to look.
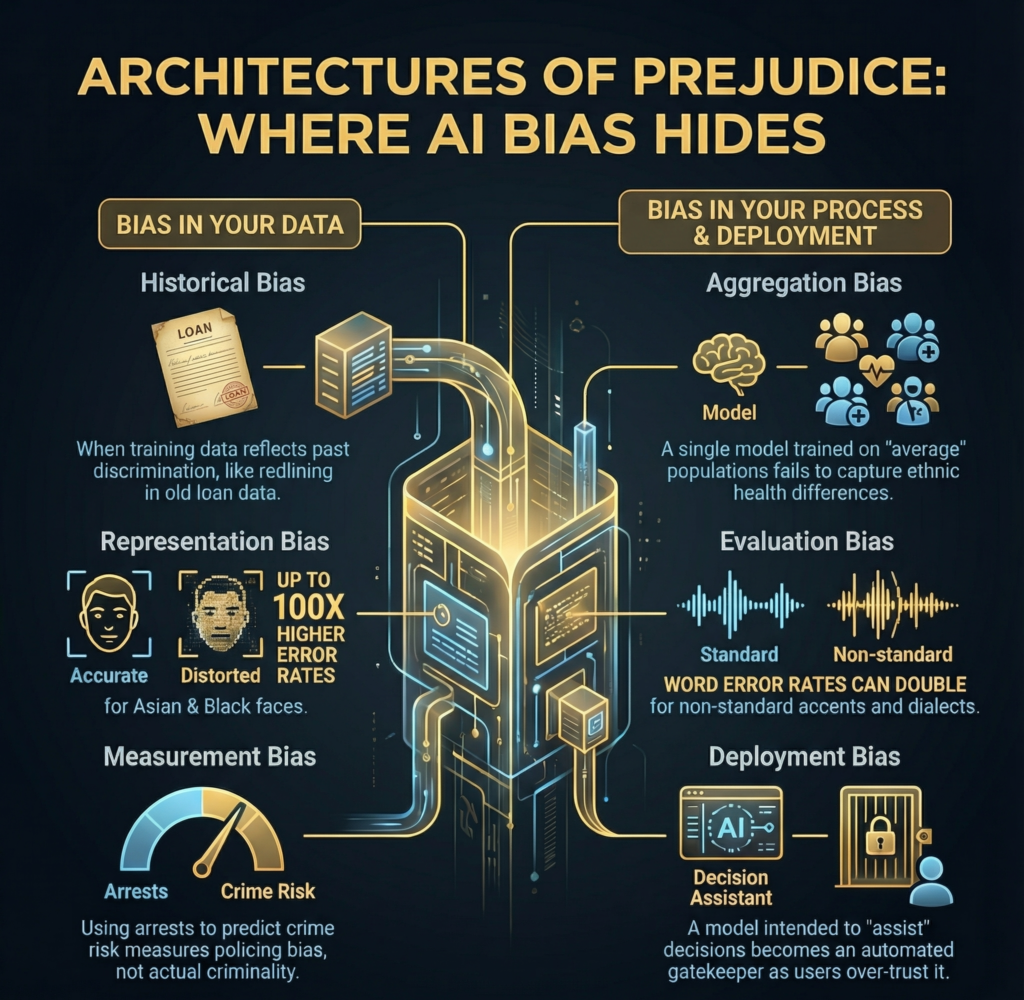
Historical bias when training data reflects past discrimination
Your dataset records history.
History includes injustice.
Loan approval data from decades ago includes redlining.
Hiring data includes exclusion.
Medical records include unequal access.
The trap
- Data looks clean
- Labels look correct
- Outcomes reflect discrimination
Your model copies it faithfully.
A World Bank analysis showed algorithmic credit scoring systems trained on historical banking data replicate exclusion patterns unless corrected.
Source worldbank dot org research archives.
Accuracy does not equal fairness.
Representation bias when your data excludes people
Some groups barely appear in your dataset.
Facial recognition systems trained mostly on light skinned faces perform far worse on darker skin tones.
This is not theory.
It is measured.
The National Institute of Standards and Technology found false positive rates up to 100 times higher for Asian and Black faces compared to white faces in some systems.
Source nist dot gov FRVT report.
Why this happens
- Convenience sampling
- Limited data access
- Geographic bias
If the model never saw you, it cannot learn you.
Measurement bias when labels encode inequality
How you measure matters more than what you measure.
Using arrest records to predict crime risk measures policing bias.
Not criminal behavior.
Using healthcare cost measures access to care.
Not illness.
Using employee performance reviews captures manager bias.
This mistake is everywhere.
I once audited a churn model where customer complaints were used as a feature.
Some users never complain.
Others complain loudly.
The model punished vocal users regardless of satisfaction.
That is measurement bias.
Aggregation bias when one model fits nobody well
Single global models assume one pattern fits all.
That assumption breaks fast.
Medical risk models trained on average populations miss ethnic differences in symptoms and disease progression.
Diabetes presents differently across groups.
Heart disease does too.
A JAMA study showed race blind clinical algorithms misestimated risk for minority populations.
Source jamanetwork dot com.
Sometimes fairness means multiple models.
That feels uncomfortable.
It works.
Evaluation bias when you test on the wrong people
Benchmarks lie when users differ from test data.
Language models tested on formal text struggle with casual speech.
Speech recognition systems tested on standard accents fail in the real world.
Google researchers reported word error rates double for African American English speakers compared to white speakers.
Source Proceedings of the National Academy of Sciences via pnas dot org.
Good test scores can hide real harm.
Deployment bias when tools become decisions
Models ship with intent.
Reality ignores it.
A decision support tool becomes an automated gatekeeper.
Humans overtrust scores.
Context disappears.
I have watched teams say the model only assists.
Then watch ops teams blindly follow it under pressure.
Bias increases after launch.
What Does Fairness Even Mean for an Algorithm
There is no single fair AI.
There are conflicting definitions.
You must choose.
Why there is no single definition of fair AI
Fairness metrics fight each other mathematically.
You cannot satisfy all at once except in rare cases.
The main concepts you will face
- Demographic parity
Equal positive outcomes across groups
Feels equal
Ignores qualification differences - Equal opportunity
Equal true positive rates
Rewards qualified people fairly
Produces different overall rates - Predictive parity
Equal precision across groups
Predictions mean the same thing
Misses more people in some groups - Individual fairness
Similar people get similar outcomes
Feels intuitive
Similarity is hard to define
Researchers proved these trade offs formally.
Source Kleinberg et al fairness impossibility theorem published via arxiv dot org.
This is not a tooling problem.
It is a values decision.
The impossibility theorem you need to know
You must choose what fairness means.
You cannot avoid it.
That choice reflects priorities.
Ethics.
Risk tolerance.
When teams say the model is neutral, they hide the choice.
They do not remove it.
How to choose the right fairness metric for your situation
Short direct guidance
- Healthcare and justice
Focus on equal opportunity
Errors harm lives - Loans and hiring
Consider demographic parity or equalized odds
Access matters - Risk scores
Focus on calibration and predictive parity
Scores must mean the same thing - Recommendations
Focus on individual and exposure fairness
Visibility shapes opportunity
The real question is uncomfortable.
Who gets to decide fairness.
Engineers often decide by default.
They should not decide alone.
Fairness Metrics Comparison Table
| Metric | What It Measures | When to Use | Tradeoff Risk |
|---|---|---|---|
| Demographic Parity | Equal positive rates | Access models | Ignores qualification |
| Equal Opportunity | Equal TPR | High stakes decisions | Diff approval rates |
| Predictive Parity | Equal precision | Calibrated scores | Miss qualified |
| Individual Fairness | Similar outcomes for similar cases | Personal decisions | Hard to define similarity |
How Do You Actually Detect Bias in Your Model
You cannot fix bias you do not see.
Detection comes first.
Always.
Short answer
Audit data. Test by group. Monitor live.
That is the workflow I follow every single time 👍
Example: Fairness Evaluation Table
| Metric | Group A | Group B | Gap | Acceptable Threshold |
|---|---|---|---|---|
| Accuracy | 0.92 | 0.85 | 7% | <5% |
| False Pos Rate | 0.05 | 0.11 | 6% | <5% |
| False Neg Rate | 0.08 | 0.14 | 6% | <5% |
Before You Train Audit Your Data
Bias usually lives inside the dataset.
Not the model.
Questions I force myself to answer before training
- Who appears in this data
- Who barely appears
- Who never appears
- What historical inequality shaped this data
- What exactly do my labels measure
- Who collected this data and why
If you skip this step, fairness later becomes damage control.
Concrete checks that work
- Demographic breakdown by count and percentage
- Correlation between features and protected attributes
- Outcome distribution by group
- Missingness patterns by group
A Google research paper showed that simple data slicing uncovered performance gaps missed by aggregate metrics in over 40 percent of production models.
Source Google AI fairness research via research dot google.
I have seen teams shocked by what a basic groupby reveals 😬
After You Train Test Across Subgroups
Overall accuracy means nothing alone.
You need per group metrics.
What I always compute
- Accuracy per demographic group
- Precision and recall per group
- False positive rates per group
- False negative rates per group
- Calibration curves per group
- Score distribution per group
Red flags you should never ignore
- More than 5 percent performance gap
- One group carries most false positives
- Confidence scores differ for similar cases
ProPublica showed COMPAS recidivism scores falsely flagged Black defendants at nearly twice the rate of white defendants.
Source ProPublica investigation via propublica dot org.
The math made bias visible.
The system already caused harm.
In Production Monitor Drift and Impact
Bias evolves.
Deployment changes behavior.
What I monitor continuously
- Outcome shifts by group over time
- Complaint and appeal rates
- Manual override frequency
- Edge cases reported by users
I once watched a fair model drift into unfairness after a policy change altered user behavior.
The data changed.
The assumptions broke.
Bias can appear after launch 🚨
Here’s a small fairness check snippet using FairLens (quick demo):
import pandas as pd
import fairlens as fl
df = pd.read_csv("your_data.csv")
fscorer = fl.FairnessScorer(
df,
target_attribute="Outcome",
sensitive_attributes=["Race", "Gender"]
)
report = fscorer.demographic_report()
print(report)
What Can You Actually Do to Make Your Model Fairer
Fairness requires intervention.
Passive observation fails.
I organize fixes by timing.
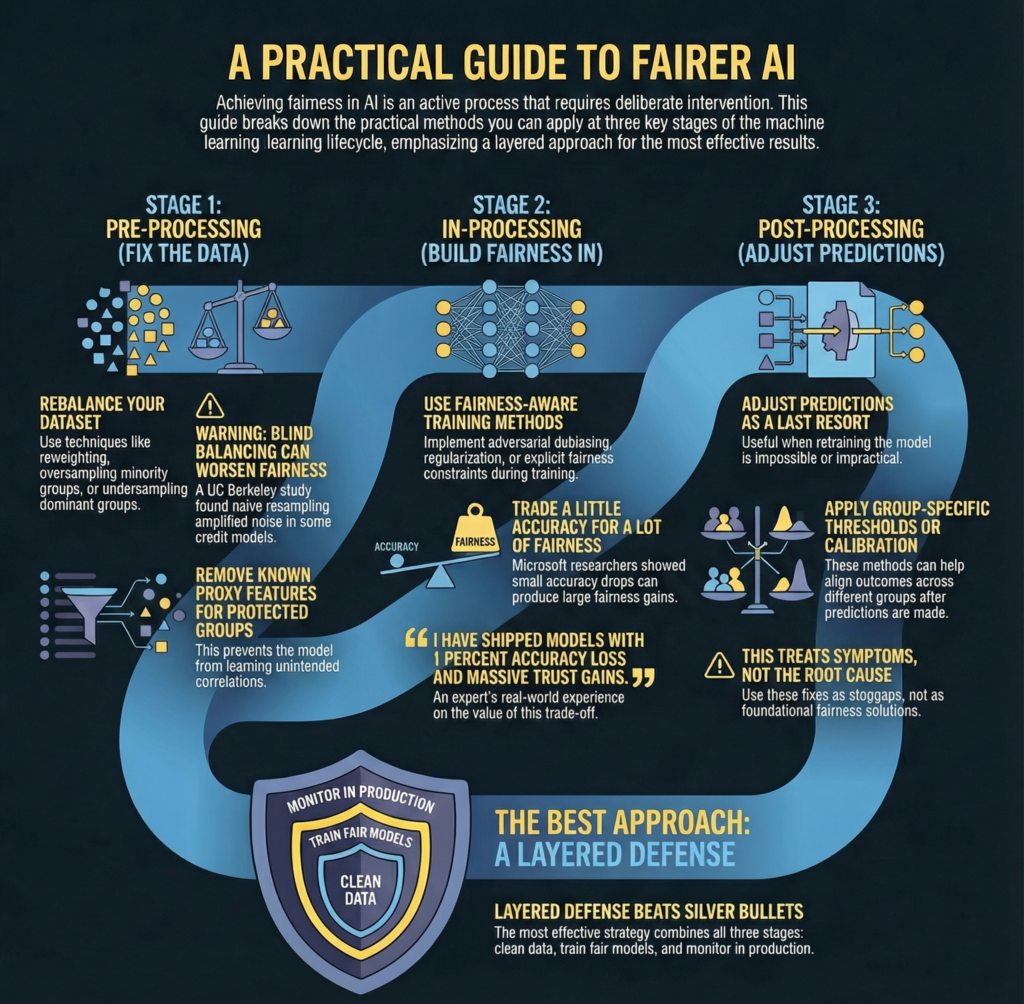
Pre Processing Fix the Data Before Training
These methods work when you control data but not model internals.
Common techniques that actually help
- Reweighting underrepresented samples
- Oversampling minority groups
- Undersampling dominant groups
- Synthetic data generation with care
- Removing known proxy features
When this works best
- Limited access to training code
- Shared datasets
- Baseline models
Warning
Blind balancing causes harm.
Understand why imbalance exists first.
A UC Berkeley study found naive resampling worsened fairness in some credit models by amplifying noise.
Source Berkeley AI research via berkeley dot edu.
In Processing Build Fairness Into Training
This is where serious work happens.
Techniques I trust
- Adversarial debiasing that blocks protected attribute inference
- Regularization that penalizes disparate impact
- Explicit fairness constraints
- Multi objective optimization
Reality check
You often trade accuracy for fairness.
That trade is worth it.
Microsoft researchers showed small accuracy drops produced large fairness gains in hiring models.
Source Microsoft research via microsoft dot com.
I have shipped models with 1 percent accuracy loss and massive trust gains 😊
Post Processing Adjust Predictions After Training
This helps when retraining is impossible.
Useful options
- Group specific thresholds
- Calibration alignment
- Reject option classification for uncertain cases
Use this carefully.
These fixes treat symptoms.
I use them as stopgaps.
Not foundations.
The Hybrid Approach That Actually Works
No single method solves bias.
What works in practice
- Clean and rebalance data
- Train with fairness aware methods
- Monitor and adjust in production
- Iterate based on feedback
Layered defense beats silver bullets.
Can You Just Remove Sensitive Attributes and Call It Fair
Short answer
No.
That approach fails quietly.
The Proxy Variable Problem
Models infer protected traits indirectly.
Common proxies
- ZIP codes correlate with race
- Names correlate with gender and ethnicity
- Browsing behavior signals income
- Purchase history signals family status
I watched a hiring model drop gender and then learn it from sports interest data.
Nothing improved.
This happens constantly.
What Actually Works Instead
Effective approaches
- Include sensitive attributes for testing
- Use fairness through awareness
- Debias embeddings directly
- Apply adversarial training
Counterintuitive truth
Sometimes you must use sensitive attributes to ensure fairness.
Researchers at Harvard showed fairness metrics fail without protected attribute access.
Source Harvard fairness research via harvard dot edu.
Who Is Responsible When a Biased Model Causes Harm
Blame spreads easily.
Accountability disappears.
The Blame Diffusion Problem
Common deflections
- The algorithm decided
- The data came like this
- Legal approved it
- Users misunderstood it
None of these protect people.
Building Accountability Into ML Workflows
What responsible teams do
- Maintain model cards with fairness sections
- Require bias audits before release
- Assign fairness owners
- Create appeal paths
- Track harm reports
Regulators care now.
The EU AI Act mandates risk management and bias mitigation for high risk AI systems.
Source European Commission via europa dot eu.
This is no longer optional.
What About the Bias We Cannot See
Fairness creates new trade offs.
You must face them honestly.
When Making the Model Fair Creates New Problems
Common second order effects
- Lower overall accuracy
- Resource allocation conflicts
- Reinforced stereotypes
- Performance ceiling effects
I have seen fairness tuning reduce outcomes for everyone.
That forced tough decisions.
Who pays the cost matters.
When Unequal Outcomes Are Actually Fair
Equality is not always fairness.
Key distinctions
- Discrimination driven differences need fixing
- Biological or contextual differences may not
Examples
- Medical risk differs by population
- Sports performance differs by league
- Disease prevalence differs by genetics
Fairness targets equal opportunity and treatment.
Not equal numbers.

How Do You Talk About Fairness With Stakeholders Who Do Not Get It
Communication decides success.
When Leadership Wants Maximum Accuracy
Ask one question
Accuracy for whom
Frame it clearly
- Biased accuracy hides risk
- Regulatory exposure is real
- Brand damage lasts years
- Fairness expands market reach
McKinsey reported companies with inclusive AI practices see higher trust and adoption.
Source McKinsey research via mckinsey dot com.
Fairness protects revenue.
When Engineers Say We Follow the Data
Data reflects choices.
Remind them
- Collection involves access decisions
- Labels involve judgment
- History embeds bias
Good engineering builds systems that work for all users.
Templates for Fairness Requirements
Practical language that works
- Model accuracy within X percent across groups
- False positive gap below Y percent
- Evaluation reflects user population
- Bias audit required before release
Make fairness measurable.
What Is the Future of Fair AI
The field is evolving fast.
Causal Fairness
Correlation misleads.
Causality clarifies.
Causal models separate legitimate factors from forbidden influence.
Example
Experience affects job performance.
Race does not.
Researchers show causal fairness improves long term equity.
Source NeurIPS fairness papers via neurips dot cc.
Participatory Machine Learning
People affected by models participate.
What this includes
- Community review of data
- Co defining fairness goals
- Real user feedback loops
Fairness becomes negotiated.
Not imposed.
Fairness Aware AutoML
Automation now includes fairness.
Emerging tools tune fairness like hyperparameters.
This lowers barriers.
Not responsibility.
Frequently Asked Questions About Bias and Fairness in ML
Can AI ever be unbiased
No.
Bias always exists.
Is biased AI illegal
Increasingly yes.
Especially in hiring lending housing.
Do I need demographic data
Often yes.
You cannot measure what you hide.
Is equal inaccuracy fair
No.
Impact differs by error type.
Can tools solve fairness
No.
They diagnose only.
Individual vs group fairness
Individual treats similar people similarly.
Group balances outcomes.
Fairness vs profit
Long term value favors fairness.
No demographic data available
You have a blind spot.
Removing bias equals fairness
No.
Fairness may require correction.
Are fairness metrics biased
Yes.
They embed values.
False positives or false negatives
Depends on harm.
Separate models per group
Sometimes yes.
Conclusion
Bias in machine learning is inevitable.
Ignoring it is optional.
Key actions
- Audit your data now
- Define fairness explicitly
- Test by group always
- Monitor continuously
- Assign accountability
Fairness is a commitment.
Not a checkbox.
Final thought
Your model already has bias.
The real question is whether you are willing to see it, own it, and fix it 💡